本文翻译自 2025 LLM Year in Review,版权归原作者所有。

2025 年对于大语言模型(LLMs)来说,是进步强劲且充满变革的一年。以下是我个人认为值得关注且略显意外的"范式转变"清单——这些改变了整个领域格局,在概念上令我印象深刻。
1. 基于可验证奖励的强化学习(RLVR)
在 2025 年初,所有实验室的 LLM 生产栈看起来都是这样的:
- 预训练(GPT-2/3,约 2020 年)
- 监督微调(InstructGPT,约 2022 年)以及
- 基于人类反馈的强化学习(RLHF,约 2022 年)
这是训练生产级 LLM 的稳定且经过验证的配方,持续了相当长的时间。2025 年,基于可验证奖励的强化学习(RLVR)作为新的主要阶段加入了这个组合。通过在多种环境(例如数学/代码谜题)中针对自动可验证的奖励训练 LLMs,模型自发地发展出对人类来说像"推理"的策略——它们学会将问题分解为中间计算步骤,并学习多种问题解决策略来回反复思考(参见 DeepSeek R1 论文的示例)。这些策略在之前的范式中很难实现,因为对 LLM 来说,最优的推理轨迹和恢复策略并不清晰——它必须通过针对奖励的优化来找到对自己有效的方法。
与 SFT 和 RLHF 阶段不同(两者都是相对较短/轻量的阶段,计算量较小的微调),RLVR 涉及针对客观(不可博弈)奖励函数的训练,允许更长时间的优化。运行 RLVR 被证明具有高性价比,这吞噬了原本用于预训练的计算资源。因此,2025 年的大部分能力进步是由 LLM 实验室消化这个新阶段的积压所定义的,总体而言,我们看到的是大小相近的 LLMs,但 RL 运行时间更长。这个新阶段的另一个独特之处是,我们获得了一个全新的调节旋钮(以及相关的缩放定律),通过生成更长的推理轨迹和增加"思考时间"来控制测试时计算的能力函数。OpenAI o1(2024 年末)是 RLVR 模型的首次演示,但 o3 的发布(2025 年初)是明显的转折点,你可以直观地感受到差异。
2. 幽灵与动物 / 参差不齐的智能
2025 年是我(我认为整个行业也是如此)首次开始以更直观的方式内化 LLM 智能的"形态"。我们不是在"进化/培养动物",而是在"召唤幽灵"。LLM 栈的一切都是不同的(神经架构、训练数据、训练算法,尤其是优化压力),所以我们在智能空间中得到非常不同的实体也就不足为奇了,用动物的视角来思考它们是不合适的。从监督比特的角度来看,人类神经网络被优化用于在丛林中部落的生存,但 LLM 神经网络被优化用于模仿人类的文本、在数学谜题中获得奖励,以及在 LM Arena 上获得人类的赞同。随着可验证领域允许 RLVR,LLMs 在这些领域附近的能力会"飙升",并且总体上表现出有趣的参差不齐的性能特征——它们同时是一个天才博学者和一个困惑且认知能力受限的小学生,随时可能被越狱攻击欺骗以窃取你的数据。
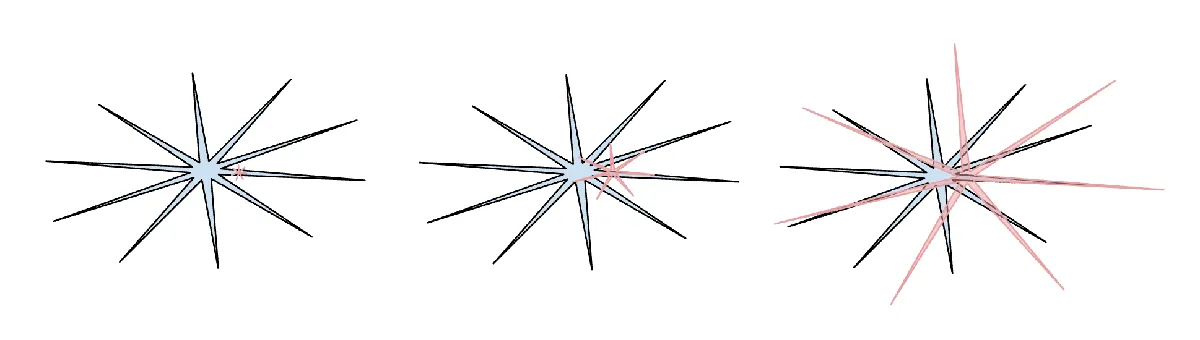 (人类智能:蓝色,AI 智能:红色。我喜欢这个版本的表情包(很抱歉我丢失了它在 X 上的原始帖子的引用),因为它指出人类智能也以其自己不同的方式参差不齐。)
(人类智能:蓝色,AI 智能:红色。我喜欢这个版本的表情包(很抱歉我丢失了它在 X 上的原始帖子的引用),因为它指出人类智能也以其自己不同的方式参差不齐。)
与此相关的是我在 2025 年对基准测试的普遍冷漠和信任丧失。核心问题是,基准测试几乎在构造上就是可验证的环境,因此立即容易受到 RLVR 和通过合成数据生成的较弱形式的影响。在典型的基准测试优化过程中,LLM 实验室的团队不可避免地会构建与基准测试所占据的嵌入空间的小部分相邻的环境,并增长参差不齐的能力来覆盖它们。在测试集上训练是一种新的艺术形式。
在所有基准测试中取得优异成绩但仍然没有实现 AGI 会是什么样子?
我在这个主题上写了更多内容:
3. Cursor / LLM 应用的新层次
关于 Cursor(除了它今年的迅速崛起),我发现最值得注意的是,它令人信服地揭示了"LLM 应用"的新层次——人们开始谈论"Cursor for X"。正如我在今年 Y Combinator 演讲中强调的那样(文字版 和 视频),像 Cursor 这样的 LLM 应用为特定垂直领域捆绑和编排 LLM 调用:
- 它们进行"上下文工程"
- 它们在后台编排多个 LLM 调用,串联成越来越复杂的 DAGs,仔细平衡性能和成本权衡
- 它们为循环中的人类提供特定于应用的 GUI
- 它们提供"自主性滑块"
2025 年,大量讨论集中在这个新应用层有多"厚"。LLM 实验室会占据所有应用,还是 LLM 应用有绿色牧场?我个人认为,LLM 实验室将倾向于培养具有一般能力的大学生,但 LLM 应用将通过提供私有数据、传感器、执行器和反馈循环,在特定垂直领域组织、微调并实际激活它们的团队,使其成为部署的专业人员。
4. Claude Code / 生活在你电脑上的 AI
Claude Code (CC) 作为 LLM Agent 的首个令人信服的演示而出现——以循环的方式将工具使用和推理串联起来进行扩展的问题解决。此外,CC 对我来说值得注意的是,它运行在你的计算机上,并使用你的私有环境、数据和上下文。我认为 OpenAI 在这方面做错了,因为他们将早期的 codex / agent 工作重点放在从 ChatGPT 编排的容器中的云部署上,而不是简单的 localhost。虽然在云中运行的智能体群感觉像是"AGI 终局",但我们生活在一个中间且足够缓慢的起飞世界中,具有参差不齐的能力,因此直接在开发者的计算机上运行智能体更有意义。请注意,真正重要的主要区别不是"AI 操作"在哪里运行(在云中、本地还是其他地方),而是其他一切——已经存在且启动的计算机、其安装、上下文、数据、秘密、配置以及低延迟交互。Anthropic 正确地把握了这个优先顺序,并将 CC 打包成一个令人愉悦的、最小化的 CLI 形式,改变了 AI 的样子——它不仅仅是一个你去访问的网站,比如 Google,它是一个"生活"在你计算机上的小精灵/幽灵。这是与 AI 交互的一种新的、独特的范式。
5. Vibe 编程
2025 年是 AI 跨越能力阈值的一年,能够仅通过英语构建各种令人印象深刻的程序,忘记代码甚至存在。有趣的是,我在这条淋浴时的思考推文中创造了"vibe 编程"这个术语,完全不知道它会走多远 :)。通过 vibe 编程,编程不再严格保留给受过高度训练的专业人员,它是任何人都可以做的事情。从这个角度来看,这是我在赋能人民:LLMs 如何颠覆技术扩散脚本中写到的另一个例子,关于(与迄今为止的所有其他技术形成鲜明对比)普通人从 LLMs 中受益远远多于专业人员、公司和政府。但 vibe 编程不仅赋能普通人接近编程,它还赋能受过训练的专业人员编写更多(vibe 编码的)软件,否则这些软件永远不会被编写。在 nanochat 中,我用 Rust 编写了自己的自定义高效 BPE 分词器,而不是采用现有库或在那个级别学习 Rust。我今年用 vibe 编程了许多项目,作为我想要存在的东西的快速应用演示(例如,参见 menugen、llm-council、reader3、HN 时间胶囊)。我还用 vibe 编程了整个短暂的应用程序,只是为了找到一个错误,因为为什么不呢——代码突然变得免费、短暂、可塑、一次性使用后可丢弃。Vibe 编程将改造软件并改变职位描述。
6. Nano banana / LLM GUI
Google Gemini Nano banana 是 2025 年最令人难以置信、改变范式的模型之一。在我的世界观中,LLMs 是下一个主要的计算范式,类似于 1970 年代、80 年代等的计算机。因此,我们将看到类似的创新,出于根本相似的原因。我们将看到个人计算的等价物、微控制器(认知核心)或智能体的互联网等等。特别是在 UIUX 方面,与 LLMs"聊天"有点像在 1980 年代向计算机控制台发出命令。文本是计算机(和 LLMs)的原始/首选数据表示,但它不是人们的首选格式,尤其是在输入时。人们实际上不喜欢阅读文本——它缓慢且费力。相反,人们喜欢以视觉和空间方式消费信息,这就是为什么在传统计算中发明了 GUI。同样,LLMs 应该以我们首选的格式与我们交流——图像、信息图表、幻灯片、白板、动画/视频、Web 应用等。当然,早期和现在的版本是诸如表情符号和 Markdown 之类的东西,它们是通过标题、粗体、斜体、列表、表格等"装扮"和布局文本以便于消费的方式。但谁将真正构建 LLM GUI?在这种世界观中,nano banana 是可能看起来像什么的第一个早期提示。重要的是,它的一个值得注意的方面是,这不仅仅是关于图像生成本身,而是关于文本生成、图像生成和世界知识的联合能力,所有这些都纠缠在模型权重中。
总结。2025 年是 LLMs 令人兴奋且略显意外的一年。LLMs 正在成为一种新型智能,同时比我预期的聪明得多,也比我预期的愚蠢得多。无论如何,它们非常有用,我认为即使在目前的能力下,行业也没有意识到其潜力的 10%。与此同时,有太多的想法可以尝试,从概念上讲,这个领域感觉非常开放。正如我今年早些时候在 Dwarkesh 播客上提到的那样,我同时(表面上矛盾地)相信我们将看到快速且持续的进步_以及_仍有很多工作要做。系好安全带。