本文翻译自 The Memory Allocator,版权归原作者所有。
在 上一篇文章 中,我们探索了 Go runtime 如何引导启动自己——一个 Go 二进制文件如何从操作系统移交控制权到你的 func main() 运行。在那个 bootstrap 过程中,runtime 设置的第一件事之一就是 内存分配器。这也是我们今天将要探讨的内容。
把内存分配器想象成一个仓库管理员。你的程序不断需要不同大小的盒子——有时很小,有时很大——而且需要 很快。分配器的工作是尽可能快地分发这些盒子,保持仓库井井有条以免浪费,并与垃圾回收器合作回收不再使用的盒子。
但在进入仓库本身之前,让我们先谈谈东西什么时候会真正放到那里。
内存分配何时发生?
并非你程序中的每个变量都会经过内存分配器。Go 有两个放置数据的地方:栈 和 堆。
栈比较简单。每个函数调用在栈上获得自己的小块临时空间,当函数返回时,该空间自动消失。它快速且简单——无需记账。
但有时数据需要在创建它的函数结束后继续存在。也许你要返回一个指向某物的指针,或者存储一个程序其他部分稍后要使用的值。这些数据不能活在栈上——函数返回时它会消失。所以它们去 堆,这是一个寿命更长的内存区域。
Go 编译器在这方面其实很聪明。它在编译时分析你的代码,决定什么可以留在栈上,什么需要去堆上——这称为 逃逸分析(我们在 IR 文章 中详细讨论过)。
每当有东西最终落在堆上,内存分配器就开始发挥作用。它是负责在堆上找到空闲空间并移交的系统。本文其余部分就是关于这个的。
一个小简化:上面的图不是完整的故事。在 Go 中,goroutine 栈实际上是从堆分配的——所以内存分配器提供栈存在的空间。但一旦栈被分配,上面的变量管理方式与堆对象非常不同:它们只是栈帧内的偏移量,每个变量没有分配器参与。所以虽然分配器负责栈 内存,但它不参与将单个变量放置在栈上。对于本文,我们将关注堆方面。
所以分配器管理堆内存。但这些内存最初从哪里来?
为什么不直接向 OS 请求?
当你的程序需要内存时,必须有人提供。最终,那个人是操作系统。OS 管理你机器上的所有物理 RAM,任何想要内存的进程都必须通过系统调用向 OS 请求,比如 Linux/macOS 上的 mmap 或 Windows 上的 VirtualAlloc。
问题是系统调用很慢。它们涉及从用户空间切换到内核空间,OS 进行自己的记账,然后再切换回来。如果 Go 每次你写 make([]byte, 100) 或 &MyStruct{} 时都进行系统调用,性能会很糟糕——尤其是在一种为高并发设计的语言中,可能有成千上万个 goroutine 同时在分配内存。
所以 Go runtime 采用不同的方法:它向 OS 预先请求大块内存(稍后我们会看到在大多数 64 位系统上是 64MB),然后在内部管理分配。当你的代码需要 100 字节时,分配器不去 OS——它从已有的内存中切出 100 字节。只有当用完时才会回到 OS。
这是内存分配器背后的基本思想。它位于你的程序和操作系统之间,充当快速中间层,通过在热路径上避免系统调用使分配变得廉价。但在内部管理所有这些内存并不简单——分配器需要跟踪什么在使用中、什么是空闲的,并且不能成为瓶颈。让我们看看它是如何做到的。
Arena 和 Page
我们说过 runtime 向 OS 请求大块内存。这些块称为 arena,在大多数 64 位系统上每个是 64MB(Windows 和 32 位系统上是 4MB,WebAssembly 上是 512KB)。
当你的程序开始并启动分配时,runtime 从 OS 请求第一个 arena。随着程序需要更多内存,它请求额外的 arena。它们在内存中不需要彼此相邻——runtime 通过内部映射跟踪所有 arena。
这是否意味着 Go 立即获取 64MB RAM? 不是。当 runtime"请求"一个 arena 时,它首先只是保留 64MB 的 地址空间——想象成在一块土地上写上你的名字但还没在上面建任何东西。此时没有使用物理内存。然后,当 runtime 实际需要使用该 arena 的部分时,它告诉 OS 以约 4MB 的块使区域可用。即使这样,OS 也不会分配真实内存,直到你的程序实际写入那些地址——物理内存按需出现,一次一个 OS page,完全透明。所以实际成本是渐进的:保留空间(基本免费),按需以 4MB 块提交(每次一个系统调用),让 OS 在后台填充物理内存。这是分配器如此快速的另一个原因——一旦内存被提交,分配器所做的所有事情都不需要与 OS 通信。
但 64MB 的块太大了,不能直接分发。如果你的程序请求 32 字节,你不想给它整个 arena。所以每个 arena 被分成 page,每个 8KB(8192 字节)。这是 Go 自己的 page 大小——与 OS page 大小不同,后者通常是 4KB。
Page 是分配器在内部工作的基本单位。当它需要满足分配时,它以 page 为单位工作——获取多少个 page、哪些 page 空闲、哪些在使用中。一个 64MB 的 arena 包含 8192 个 page(64MB / 8KB),runtime 跟踪每个 page 的状态。
但 8KB 对于大多数分配来说仍然太大。你不需要整个 page 来存放一个 32 字节的 struct。这就是 span 发挥作用的地方。
Span:对象居住的地方
span 是一个或多个连续的 page,专门用于存放 单一大小 的对象。这是分配器实际将内存交给你的程序的层级。
让我们具体化一下。假设你的程序需要一堆 32 字节的对象。分配器会获取一个 page(8KB),将其转换为 32 字节对象的 span,并将其分成 256 个槽位(8192 / 32 = 256)。每个槽位正好可以容纳一个对象。当你分配一个 32 字节的对象时,分配器只需在该 span 中找到下一个空闲槽位并返回它。当你需要另一个时,它获取下一个空闲槽位。快速而简单。
这之所以有效,因为 span 中的每个槽位大小相同。无需搜索合适的块,span 内没有碎片,无需合并相邻的空闲块。只需找到一个空闲槽位并使用它。为了找到那个空闲槽位,每个 span 保持一个 称为 allocBits 的位图——每个槽位一个位,1 表示"使用中",0 表示"空闲"。找到下一个空闲槽位就是扫描下一个 0 位。span 还跟踪它在内存中的起始位置、覆盖多少个 page、有多少个槽位、当前分配了多少个。还有第二个位图叫 gcmarkBits,垃圾回收器使用它——但我们稍后会讲到。所有这些元数据都是 span 结构本身的一部分——runtime 分配的一个独立对象来管理 span——不存储在存放你对象的 page 中。所以 page 的完整 8KB(或 span 覆盖的任意多个 page)都可用于对象槽位。
Size Class
现在,如果每个 span 只存放一种大小的对象,我们需要不同大小的 span。但分配器不能为每个可能的字节数创建 span——那将难以管理。相反,Go 定义 68 个 size class,范围从 8 字节到 32KB。当你分配,比如,20 字节时,Go 将其向上取整到最近的 size class(本例中是 24 字节),并使用该 class 的 span。我们因取整损失几个字节,但简单性和速度值得。
以下是一些示例:
| Class | 对象大小 | Span 大小(Page) | 每个 Span 的对象数 |
|---|---|---|---|
| 1 | 8 B | 8 KB (1 page) | 1024 |
| 4 | 32 B | 8 KB (1 page) | 256 |
| 10 | 128 B | 8 KB (1 page) | 64 |
| 32 | 1024 B | 8 KB (1 page) | 8 |
| 41 | 3072 B | 24 KB (3 page) | 8 |
| 46 | 5376 B | 16 KB (2 page) | 3 |
| 51 | 8192 B | 8 KB (1 page) | 1 |
| 60 | 18432 B | 72 KB (9 page) | 4 |
| 65 | 27264 B | 80 KB (10 page) | 3 |
| 67 | 32768 B | 32 KB (4 page) | 1 |
如果你查看表格,page 数量可能看起来有点随机——为什么 18KB 对象需要 9 个 page,而 8KB 对象只需要 1 个?规则其实很简单:从 1 个 page 开始,不断添加 page,直到 末尾的浪费空间(无法再容纳另一个对象的剩余字节)小于 span 的 12.5%。对于像 32 字节这样的小对象,一个 page 正好容纳 256 个对象,零剩余——完美,不需要更多 page。对于像 3KB 或 5KB 这样的中等大小,单个 page 会在末尾留下太多不可用的空间,所以 span 增长到 2、3,甚至多达 10 个 page 来减少浪费。
你可能会注意到一些 class 每个 span 只容纳 1 个对象——比如 class 51(8KB)或 class 67(32KB)。这意味着在单次分配后,span 就满了。使用更多 page 让 span 容纳更多对象不是更好吗?不一定。更大的 span 意味着即使你只需要一两个该大小的对象,也有更多内存处于保留状态。对于像 32 字节这样的小对象,程序通常一次分配数百个,将 256 个打包到 span 中有意义。但对于较大的对象,大多数程序只需要几个,所以保持 span 小可以避免浪费内存。
所以 size class 系统处理了从 8 字节到 32KB 的常见范围。但不是所有东西都能整齐地适合这个范围。
边界:大对象和微小对象
你可能注意到一些奇怪的地方:我们说有 68 个 size class,但表格从 1 到 67——只有 67 个。缺失的那个在哪里?那是 size class 0,保留给 大于 32KB 的对象。与其他 class 不同,它没有固定的对象大小或 span 大小。相反,class 0 span 正好获取对象所需的 page 数量,没有槽位细分——一个对象,一个 span。
在另一端,非常小的对象如 bool 或 int8 遇到不同的问题。最小的 size class 是 8 字节,所以即使是 1 字节的值也会获得 8 字节的槽位——对于这么小的东西来说浪费很多。为了解决这个问题,Go 有一个 tiny allocator,它将多个微小对象(小于 16 字节,无指针)打包到单个 16 字节的块中。所以几个布尔值或小整数可以共享一个槽位,而不是每个都有自己的。这大大减少了分配大量小值的程序的浪费。
我们看到了 span 如何按大小组织——但大小不是分配器关心的唯一事情。
Span Class:大小 + 指针
分配器不仅关心对象 大小——它还关心对象是否包含 指针。为什么?因为垃圾回收器需要扫描包含指针的对象以跟随引用并找到存活数据。不包含指针的对象(如 [100]byte 或只有整数的 struct)可以在 GC 期间安全跳过——没有东西可跟随。
所以 Go 为每种情况保持单独的 span:一个用于需要扫描的对象(scan),一个用于不需要的对象(noscan)。size class 和 scan/noscan 标志的组合称为 span class。68 个 size class,每个有 2 个变体,总共 136 个 span class。
有了所有这些,完整图景如下:
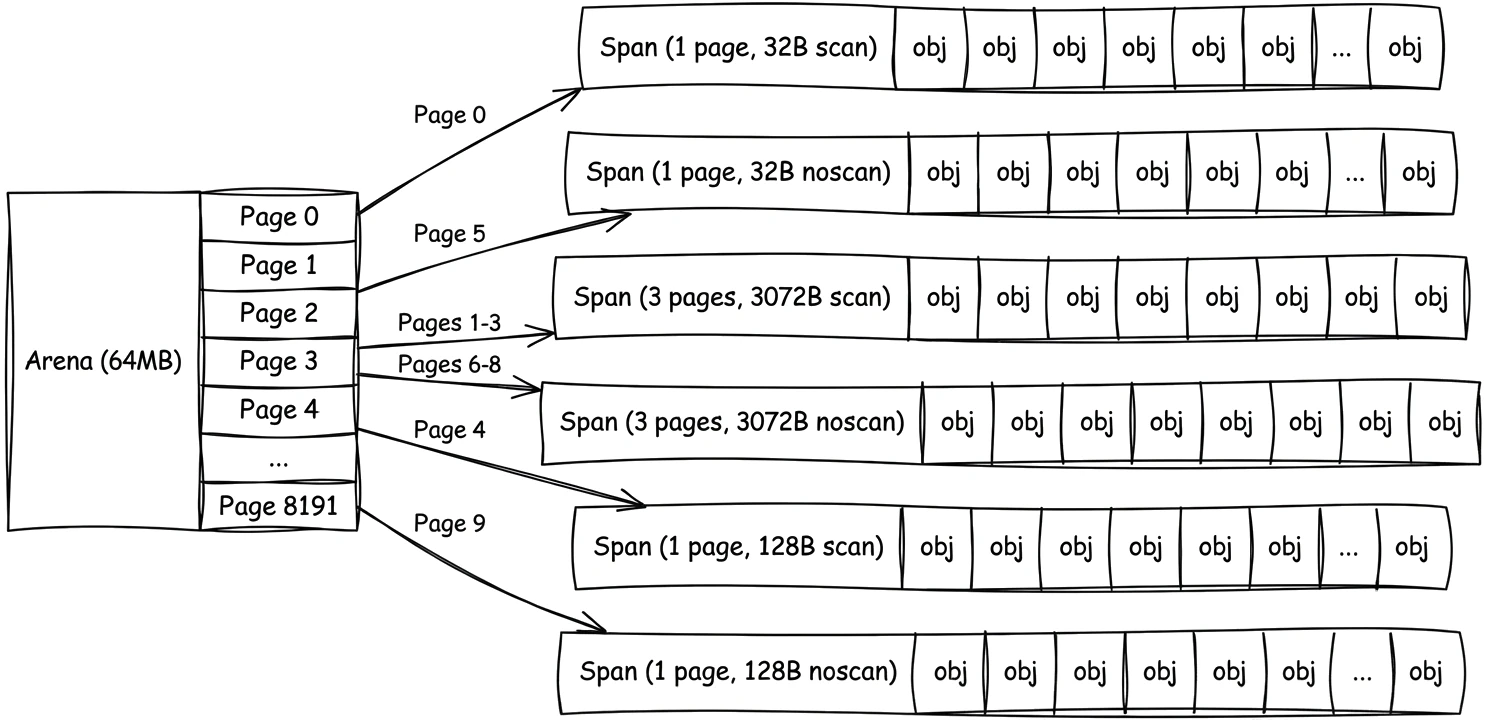
分配器向 OS 请求 arena,将它们分成 page,将 page 分组为 span,将 span 分成固定大小的槽位。每一层使下一层变得可管理。但我们还没有谈到一个大问题:Go 程序同时运行许多 goroutine,它们都需要分配内存。你如何保持所有这些有序,而不使分配器成为瓶颈?
锁问题
到目前为止,我们看到了内存如何组织——arena、page、span、槽位。但有一个关键问题我们还没有解决:当 多个 goroutine 同时尝试分配内存时会发生什么?
想象你有一个 span 的全局列表。每次任何 goroutine 需要内存时,它必须获取锁,找到空闲槽位,然后释放锁。当数千个 goroutine 并发运行时,该锁成为瓶颈——goroutine 花更多时间相互等待而不是实际做有用的工作。
这是锁问题,解决它是 Go 分配器设计最重要的方面之一。解决方案是 三级层次结构,每层有不同的范围和不同的锁定行为:
级别 1:mcache(每 P,无锁)
记得在 bootstrap 文章 中,Go 的调度器有固定数量的 P(处理器),通常每个 CPU 核心一个。每个 P 有自己的 mcache——每个 span class 一个 span 的私有集合。当在 P 上运行的 goroutine 需要分配时,它从 P 的 mcache 获取槽位。因为一次只有一个 goroutine 在 P 上运行,不需要锁。这是快速路径,处理了绝大多数分配。
级别 2:mcentral(每 span class,短暂锁)
当 mcache 的特定 span class 的 span 满了时,它需要一个新的。这就是 mcentral 发挥作用的地方。每个 136 个 span class 有一个 mcentral,它持有 span 的共享池。mcache 将其满的 span 返回给 mcentral,并获取一个新的有空闲槽位的 span。这需要锁,但很短暂——只是交换一个 span。因为每个 span class 有自己的 mcentral,分配不同大小或 scan/noscan 变体的 goroutine 不会相互竞争。
级别 3:mheap(全局,昂贵锁)
当 mcentral 没有更多 span 可以分发时,它向 mheap 请求新 page 来创建新 span。mheap 是全局 page 分配器——只有一个,访问它需要全局锁。这是慢速路径。它涉及搜索空闲 page,可能向 OS 请求新 arena,并初始化新 span。但它很少发生,因为上面的层级吸收了大部分需求。
这也是我们之前提到的大对象(>32KB)最终到达的地方——它们跳过 mcache 和 mcentral,直接去 mheap。
整个设计像缓存链一样工作:
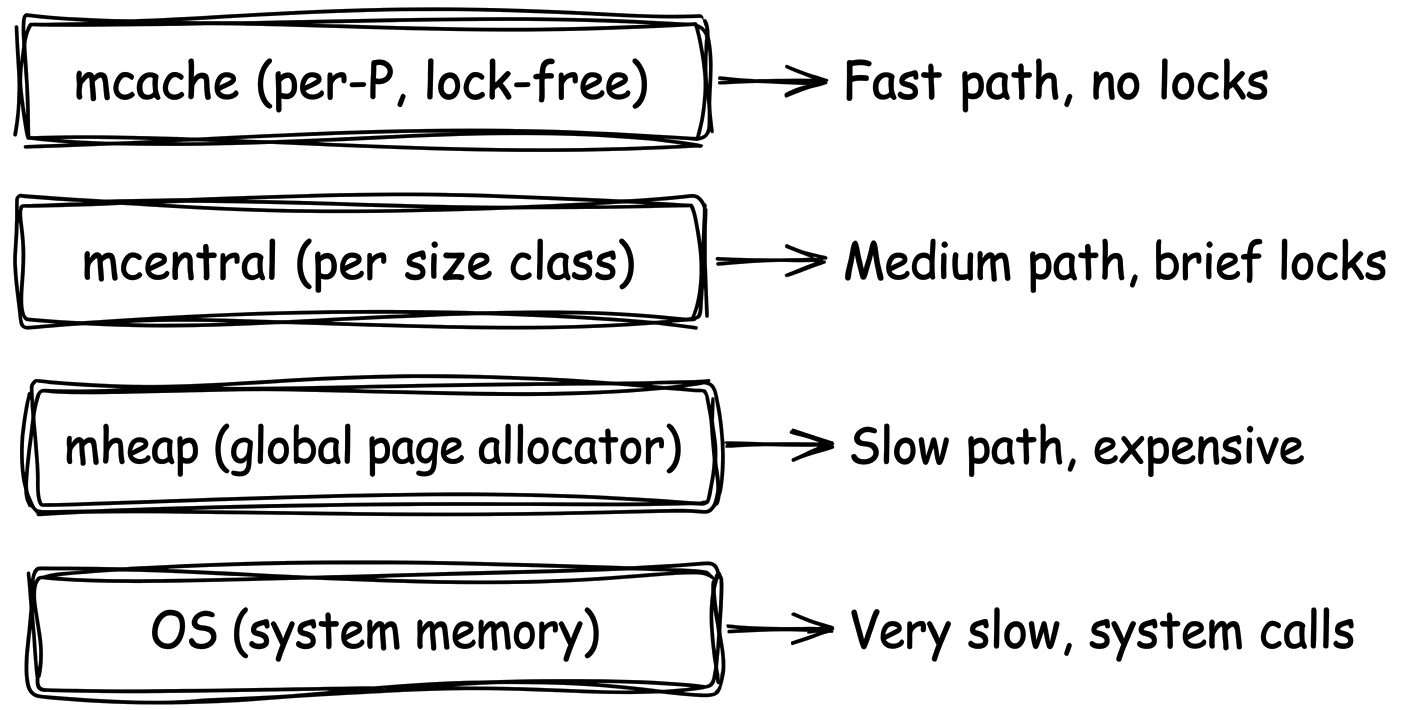
每一层作为下一层的缓存。快速路径无锁,中等路径使用细粒度锁,慢速路径在实践中罕见到其成本不重要。这是基于称为 tcmalloc(Thread-Caching Malloc)的方法,最初由 Google 为 C/C++ 程序设计,但为 Go 的特定需求进行了适配。
现在我们理解了结构和层次结构,让我们一步步看看实际发生了什么。
分配流程
一切都通过 runtime 中的单个函数:mallocgc() 在 src/runtime/malloc.go 中。
它做的第一件事是检查分配的大小。根据对象有多大,它走非常不同的路径。让我们从最简单的情况开始。
零大小分配
一个有趣的边界情况:如果你分配零大小的东西,如 struct{}{} 会怎样?Go 不费心分配任何东西——所有零字节分配返回指向同一全局变量(zerobase)的指针。这是安全的,因为你永远不能实际通过零大小对象读取或写入。
现在对于真正的分配,从最小的开始。
微小对象
对于无指针的微小对象——如 bool、int8 或小的无指针 struct——分配器使用我们之前提到的 tiny allocator。mcache 跟踪 当前 tiny block(只是来自 size class 2 span 的普通 16 字节槽位——没什么特别的)和 offset,标记该块到目前为止使用了多少。
当 tiny 分配到来时,分配器首先将大小向上取整以进行适当的对齐(根据对象大小取整到 2、4 或 8 字节),然后检查当前 tiny block 从当前 offset 到末尾是否有足够空间。如果适合,分配器返回指向 block + offset 的指针并推进 offset。所以 1 字节的 bool 后跟 1 字节的 int8 会被打包在同一个 16 字节块内彼此相邻。
当当前 tiny block 没有足够空间时,分配器从 mcache 的 size class 2 span 获取新的 16 字节槽位(使用正常的小对象路径),并将对象放在其开头。但这里有一个微妙的细节:分配器不盲目切换到新块。它比较旧块剩余多少空闲空间与新块剩余多少(即 16 减去刚放置的对象大小)。剩余空间更多 的块成为当前 tiny block。这最小化浪费——分配器总是偏好有最多空间用于未来 tiny 分配的块。无论如何,你请求的对象从新槽位返回;只是哪个块保持"当前"用于下一个 tiny 分配的问题。
因为 tiny allocator 捕获了所有小于 16 字节的无指针对象,它最终吸收了大多数你期望落在最小 size class 中的东西。在实践中,8 字节 size class(class 1)专门用于 确实 包含指针的 8 字节值——如 *int 或单指针 interface。int64 尽管是 8 字节,却通过 tiny allocator 而不是。
一旦对象是 16 字节或更大(或包含指针),tiny allocator 不适用,我们进入主分配路径。
小对象(16B 到 32KB)
这是最常见的路径,也是整个层次结构优化的路径。流程如下:
- 向上取整到最近的 size class 并确定 span class(大小 + scan/noscan)。
- 检查 mcache:查看该 span class 的 span,使用位图找到下一个空闲槽位。如果有空闲槽位,返回它。完成——无锁,只是一些位操作。
- 如果 span 满了,mcache 将其返回给 mcentral 并请求一个新的有空闲槽位的 span。mcentral 首先查找它已有的 span。如果找到尚未被垃圾回收器 sweep 的 span,它先 sweep 然后移交。
- 如果 mcentral 没有,它请求 mheap 分配新 page 并创建新 span。
- 如果 mheap 没有足够空闲 page,它从操作系统请求新 arena。
大多数分配在步骤 2 停止。步骤 3-5 发生的频率逐渐降低,这就是系统性能良好的原因。
最后,大的那些。
大对象(> 32KB)
如前所述,这些完全跳过 mcache 和 mcentral,直接去 mheap,它分配正好需要的 page。
我们看到了内存如何分配,但相反的方向呢——内存如何释放?
垃圾回收集成
内存分配器不单独工作——它与 垃圾回收器 紧密连接。我们将在未来的文章中详细探索垃圾回收器,但了解它们交互的基本原理值得,因为它影响分配器的行为。
垃圾回收器的工作是弄清楚堆上哪些对象仍在使用,哪些是垃圾。它通过遍历对象图来完成——从已知根(全局变量、栈变量等)开始,跟随指针找到所有可达的东西。任何它无法到达的都是死的,可以释放。
这就是每个 span 中的 两个位图 发挥作用的地方。每个 span 有 allocBits 位图(哪些槽位已分配)和 gcmarkBits 位图(GC 发现存活的槽位)。在 GC 周期期间,收集器在 gcmarkBits 中标记存活对象。标记完成后,runtime 交换两个位图——所以 allocBits 现在只反映存活对象,所有未标记的东西实际上被释放。分配器然后可以重用那些槽位。
这也解释了你在分配流程中可能注意到的东西:当 mcentral 将 span 交给 mcache 时,有时需要先 sweep 它。Sweep 是查看 span 的位图并确定 GC 周期后哪些槽位空闲的过程。分配器懒惰地做这个——它不一次 sweep 所有 span,而是按需在需要新分配时 sweep 它们。这分散了 sweep 的成本,跨越所有分配,而不是一次大的暂停。
如果 span 在 sweep 后完全空了(每个对象都是垃圾),它的 page 返回给 mheap,可以重用于不同的 span class。
所以 GC 弄清楚什么是死的,分配器回收那些槽位。但还有一个问题:那些内存有任何返回操作系统的吗?
内存释放和 Scavenging
当垃圾回收器释放对象时,它们不返回操作系统。槽位只是在它们的 span 中再次可用,准备下一次分配。Page 保留在 runtime 中——从 OS 的角度来看,你的程序仍然使用所有那些内存。
但如果你的程序有一个大的活动峰值,分配了大量内存,现在大部分是垃圾呢?你会有一堆空闲 page 坐在 mheap 中什么都不做,而 OS 认为你的程序仍在使用所有内存。
这就是 scavenger 发挥作用的地方。它是一个后台 goroutine,定期查找一段时间未使用的空闲 page,并告诉 OS 它可以回收它们。Page 保留在程序的地址空间中映射(所以 runtime 可以稍后重用它们而不需要新系统调用),但 OS 知道它可以拿回后面的物理内存。在 Linux 上,这是通过 MADV_DONTNEED 完成的——一个提示,说"我现在不需要这个内存,随意在其他地方使用"。
这是一个平衡行为。过早返回内存会损害性能——如果程序很快又需要该内存,它将不得不重新 fault 回来。但持有太多未使用的内存浪费系统资源。Scavenger 试图找到正确的平衡。
总结
让我们回顾一下我们涵盖的内容。在编译时,逃逸分析决定哪些值需要在堆上生存。在运行时,内存分配器是实际管理那些堆内存的。不是每次向 OS 请求,runtime 预先获取大块 64MB arena,并将它们细分为 8KB page。Page 分组为 span,每个 span 存放单一大小的固定大小槽位——68 个 size class 之一,范围从 8 字节到 32KB。scan/noscan 区别将其加倍为 136 个 span class,以便垃圾回收器可以跳过没有指针的对象。
为了避免锁竞争,分配器使用三级层次结构:mcache(每 P,无锁)处理大多数分配,mcentral(每 span class,短暂锁)用新 span 填充 mcache,mheap(全局)在其他都耗尽时分配 page。微小对象被打包在一起,大对象完全绕过层次结构。
分配器通过每个 span 上的双位图与垃圾回收器携手工作,scavenger 确保未使用的内存最终返回给 OS。
如果你想自己探索实现,runtime 源码在 src/runtime/malloc.go、mheap.go、mcache.go 和 mcentral.go 中有很好的注释,令人惊讶地易读。
在下一篇文章中,我们将查看 调度器——runtime 中决定哪个 goroutine 在哪里运行的部分,以及它如何将数千个 goroutine 多路复用到少数 OS 线程上。