本文翻译自 The Scheduler,版权归原作者所有。
在 上一篇文章 中,我们探索了 Go 的内存分配器如何管理堆内存——从 OS 获取大块 arena,将它们分成 span 和 size class,并使用三级层次结构(mcache、mcentral、mheap)使大多数分配无锁。一个关键细节是每个 P(处理器)都有自己的内存缓存。但我们从未真正解释 P 是什么,或者 runtime 如何决定哪个 goroutine 在哪个线程上运行。这是调度器的工作,也是我们今天探索的内容。
调度器是 runtime 中回答一个看似简单问题的部分:哪个 goroutine 接下来运行? 你的程序中可能有数百、数千,甚至数百万个 goroutine,但你只有少数几个 CPU 核心。调度器的工作是将所有这些 goroutine 多路复用到少数 OS 线程上,保持每个核心忙碌,同时确保没有 goroutine 被饿死。
如果你曾经使用过 goroutine 和 channel,你已经从调度器中受益而不自知。每个 go 语句、每个 channel 发送和接收、每个 time.Sleep——它们都与调度器交互。让我们看看它是如何工作的。
让我们从基本构建块开始——整个调度器围绕的三个结构。
GMP 模型
调度器围绕三个概念构建,通常称为 GMP 模型:G(goroutine)、M(machine/OS 线程)和 P(processor)。我们在 bootstrap 文章中提到了这些,但现在让我们正式看看它们。
让我们逐一查看。
G — Goroutine
G 是 goroutine——Go runtime 对并发工作片段的表示。每次你写 go f(),runtime 创建(或重用)一个 G 来跟踪该函数的执行。
G 实际携带什么?结构体有很多字段,但对我理解其工作原理最有用的是:一个小 栈(从仅 2KB 开始),一些 保存的寄存器(栈指针、程序计数器等),以便调度器可以暂停它并在稍后恢复它,一个 状态 字段跟踪 goroutine 在做什么(运行、等待、准备运行),以及一个指向当前运行它的 M 的指针。src/runtime/runtime2.go 中的完整结构体还有更多——用于 panic 和 defer 处理的字段、GC 辅助跟踪、分析标签、定时器等。
与 OS 线程相比,后者通常从 1–8MB 栈开始并携带大量内核状态。goroutine 显著 更轻——这就是为什么你可以在单个程序中有数百万个它们。OS 线程?在几千个时你开始感到压力。
所以 goroutine 是工作。但必须有人实际执行那个工作——CPU 不知道 goroutine 是什么。它只知道如何运行线程。
M — Machine(OS 线程)
M(在 src/runtime/runtime2.go 中定义)是 OS 线程——实际执行代码的东西。调度器的工作是将 goroutine 放到 M 上以便它们可以运行。
每个 M 有两个值得了解的 goroutine 指针。第一个是 curg——当前在该线程上运行的用户 goroutine。那是你的代码。第二个是 g0——每个 M 都有自己的。g0 是一个特殊 goroutine,保留给 runtime 自己的内部维护——调度决策、栈管理、垃圾回收记账。它比常规 goroutine 的栈大得多:通常 16KB,尽管根据 OS 和是否启用 race 检测器,它可能是 32KB 或 48KB。与常规 goroutine 不同,g0 栈 不增长——它在分配时固定,所以必须足够大以处理 runtime 需要做的任何事情。当调度器需要做决策(运行哪个 goroutine 接下来、如何处理阻塞操作)时,它从你的 goroutine 切换到这个 M 的 g0 来做那项工作。将 g0 视为 M 的"管理模式"——它运行调度逻辑,然后将控制权交还给用户 goroutine。
M 还有一个指向它当前附加的 P 的指针。这很重要:没有 P,M 无法运行 Go 代码。它只是一个空闲的 OS 线程坐在那里什么都不做。M 为什么需要 P?
P — Processor
这是设计的巧妙部分。P(在 src/runtime/runtime2.go 中定义)不是 CPU 核心也不是线程——它是一个 调度上下文。把它想象成一个工作站:它有 goroutine 高效运行所需的一切,M 必须坐在一个前面才能做任何实际工作。
为什么不直接让 M 运行 goroutine?问题是系统调用。当 M 进入内核时,整个 OS 线程阻塞——如果所有调度资源都附加到 M 上,它们也会被卡住。运行队列、内存缓存,所有东西都会冻结直到系统调用返回。通过将所有这些放在单独的 P 上,runtime 可以从阻塞的 M 分离 P 并将其交给空闲的 M。即使线程卡住,工作也会继续。
所以每个 P 携带自己的 本地运行队列——最多 256 个准备运行的 goroutine 列表。它还有一个 runnext 槽位,就像下一个要执行的 goroutine 的快速通道。有一个 gFree 列表,完成的 goroutine 放在那里以便可以回收而不是从头分配。它甚至携带自己的 mcache——我们在 内存分配器 文章中看到的每 P 内存缓存。因为每个 P 都有所有这些东西的副本,使用它的线程不需要一直争夺共享锁——这是一个不错的额外好处。
P 的数量由 GOMAXPROCS 控制,默认为 CPU 核心数。所以在 8 核机器上,你有 8 个 P,意味着任何时候最多 8 个 goroutine 可以真正并行运行。但你可以有比 P 多得多的 M——一些可能阻塞在系统调用中,而其他正在积极运行 goroutine。关键是任何时候只有 GOMAXPROCS 个可以运行 Go 代码。
这种解耦是调度器设计的核心,我们将在本文的其余部分看到为什么它如此重要。
所以我们有 G、M 和 P——但必须有人跟踪它们所有。那就是 schedt 结构体。
调度器状态(schedt)
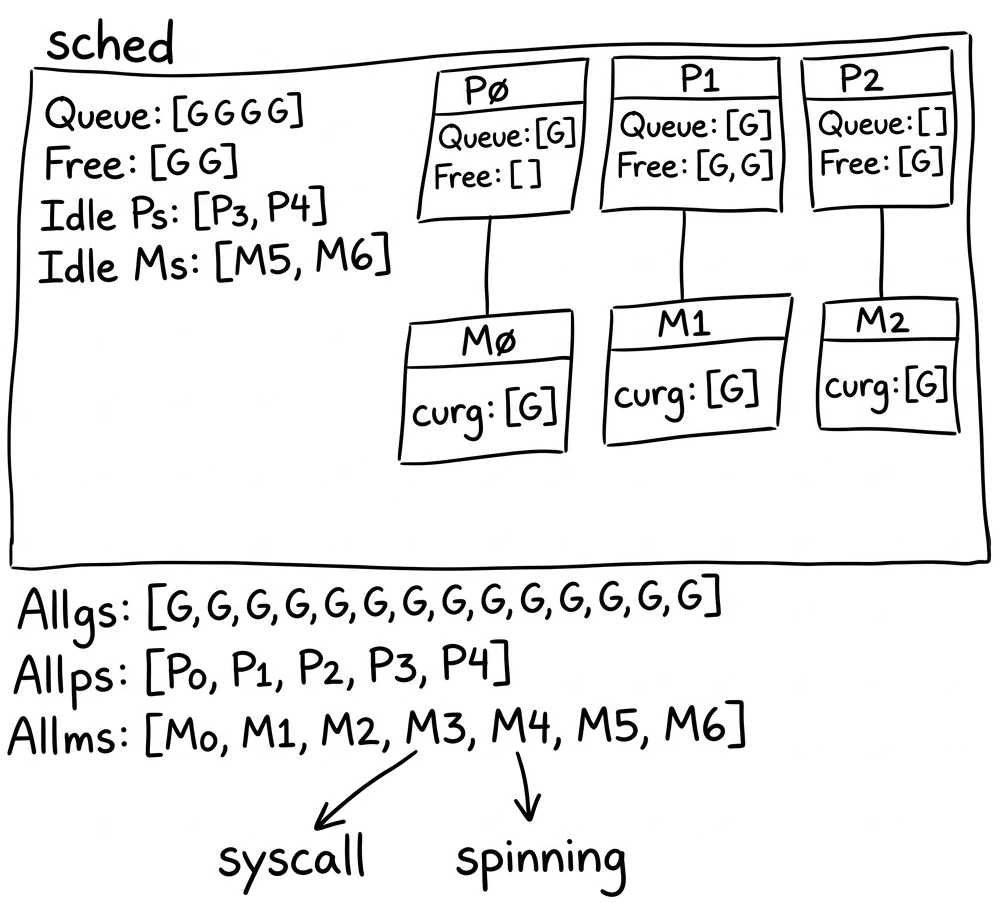
schedt 结构体(在 src/runtime/runtime2.go 中定义)是全局调度器状态。正好有一个实例——一个名为 sched 的全局变量——它持有不属于任何特定 P 或 M 的所有东西。将其视为 Ps 和 Ms 在需要协调时检查的共享公告板。
那里有什么?首先,全局运行队列(runq)——不在任何 P 的本地队列中的 goroutine 链表。这些是从满的本地队列溢出的 goroutine,或从系统调用回来找不到 P 的 goroutine。还有一个 全局空闲列表(gFree)等待回收的死 goroutine——当 P 的本地空闲列表用完时,它从这里补充,当 P 有太多死 goroutine 时,它把一些放回。我们在内存分配器中看到的相同两级模式:本地缓存用于快速路径,共享池作为备份。
然后是 空闲列表。当 P 没有 M 运行它时,它进入 pidle 列表。当 M 没有工作和 P 时,它进入 midle 列表并睡眠。调度器还跟踪当前有多少 M 正在 旋转(寻找工作)在 nmspinning 中——我们将在 稍后解释旋转的含义——以及 GC 是否请求 stop-the-world 暂停 在 gcwaiting 中。所有这些共享状态都由 sched.lock 保护——但锁设计为非常短暂地持有,因为热路径(从本地队列选择 goroutine)根本不接触 schedt。
除了 schedt,runtime 保持 主列表 每个曾经创建过的 G、M 和 P——全局变量 allgs、allm 和 allp。这些不用于调度决策。它们存在是为了 runtime 需要做全局事情时能找到 所有东西,比如在垃圾回收期间扫描所有 goroutine 栈或在 sysmon 中检查卡住的系统调用。
这是完整图景:
现在我们已经搭建了舞台,是时候看到演员行动了。让我们跟随 goroutine 通过它的生命周期,看看它如何在这个战场上移动。
Goroutine 的一生
让我们跟随 goroutine 从出生到死亡——有时甚至重生。状态在 src/runtime/runtime2.go 中定义,但与其列出它们,不如让我们走过这个故事。
出生:创建和第一步
它始于你写 go f()。编译器将其转换为对 newproc() 的调用(在 src/runtime/proc.go 中),runtime 需要一个 G 结构体来表示这个新 goroutine。但它不一定从头分配一个——首先,它检查当前 P 的死 goroutine 本地空闲列表。如果有可用的,它被回收,包括栈。如果本地列表为空,它尝试从 schedt 中的 全局空闲列表 获取一批。只有当两者都为空时,runtime 才分配一个新的 G 带新的 2KB 栈。这种重用是 goroutine 创建如此廉价的原因——大多数时候,它只是从列表中拉出一个 G 并重新初始化几个字段。
如果 G 是从空闲列表回收的,它已经在 _Gdead 状态——那是 goroutine 完成时去的地方。如果是新分配的,它从 _Gidle 开始(一个空白结构体,从未使用过)并立即转换到 _Gdead。无论哪种方式,G 在设置开始前都在 _Gdead。等等——已经死了?是的,但只是技术上。_Gdead 意味着"不被调度器使用"——它是正在设置或完成并等待重用的 goroutine 的状态。runtime 将其用作安全的"停放"状态,同时它配置 G 的内部。
在初始化期间,runtime 准备 goroutine 以便准备运行。它设置 栈指针 到栈的顶部,将 程序计数器 指向你的函数以便它知道从哪里开始执行,并放置一个指向 goexit 的返回地址——goroutine 清理处理器。这样,当你的函数完成并返回时,执行自然地落在 goexit 中而不需要任何特殊的"完成了吗?“检查。
设置完成后,G 移动到 _Grunnable 并进入当前 P 的 runnext 槽位,替换之前在那里的一切。这意味着新 goroutine 将很快运行——就在当前 goroutine 让出之后。
现在 goroutine 活着了——坐在运行队列上,准备执行,只等待 M 拾取它。
运行
当调度器从队列中拾取这个 G 时,它转换到 _Grunning。这是活动状态——goroutine 在 M 上执行你的代码,带有 P。这是它度过生产时间的地方。
但 goroutine 很少直接运行到完成。在某个时候,某件事会中断流程,接下来发生什么取决于 goroutine 停止的 原因。这里是故事分支的地方。
阻塞和解除阻塞
也许 goroutine 尝试从空 channel 接收,或获取锁定的互斥锁,或睡眠。这里有一个可能让你惊讶的细节:没有外部的"调度器线程” swoop 进来并停放 goroutine。goroutine 自己停放自己。
假设你的 goroutine 在空 channel 上做 <-ch。channel 实现看到没有东西可接收,所以它调用 gopark() 停放 goroutine 直到值到达。goroutine 切换到 g0 栈,将其自己的状态更改为 _Gwaiting,并将自己添加到 channel 的等待队列。之后,它从调度器的角度来看消失了——不在任何运行队列上,只是坐在 channel 的内部等待列表上。M 不会睡眠。它调用 schedule() 并拾取下一个 goroutine。从 M 的角度来看,一个 goroutine 停放了,另一个开始运行——M 一直保持忙碌。
gopark() 还记录 goroutine 阻塞的 原因——channel 接收、互斥锁锁定、睡眠、select 等。这是当你查看 goroutine 转储或分析数据时显示的内容,所以你可以确切知道每个 goroutine 在等待什么。
现在看另一方面:当 goroutine 等待的事情最终发生时会发生什么?假设另一个 goroutine 在该 channel 上发送值。发送者在 channel 的等待队列中找到我们的 goroutine,直接将值复制给它,并调用 goready()。这将 goroutine 的状态改回 _Grunnable 并将其放在发送者的 runnext 槽位中——意味着它很快运行,就在发送者让出之后。这个 runnext 放置在生产者和消费者 goroutine 之间创建紧密的来回。G1 发送,G2 接收并立即运行,G2 发送回来,G1 接收并立即运行——几乎像协程相互交接,调度开销最小。
系统调用
阻塞在 channel 和互斥锁是一回事——goroutine 停放,但 M 和 P 保持空闲。系统调用是不同的野兽,因为它们阻塞整个 OS 线程。
当 goroutine 进行系统调用——读取文件、接受网络连接、任何进入内核的东西——整个 OS 线程阻塞。在进入内核之前,goroutine 调用 entersyscall(),它保存其状态并将其状态更改为 _Gsyscall。但这里有一个重要细节:M 不放弃它的 P。它保留它。为什么?因为大多数系统调用很快——几微秒——goroutine 会回来并在同一个 P 上继续运行,就像什么都没发生一样。无锁、无协调、无开销。
但一旦 goroutine 在 _Gsyscall 中,它就处于 失去 P 的危险中。如果系统调用花费太久,sysmon 可以来并 重新获取 P——从阻塞的 M 分离它并将其交给另一个线程,以便其运行队列中的 goroutine 继续运行。这是 G-M-P 解耦真正发挥作用的地方:线程卡在内核中,但工作继续。
当系统调用完成时,goroutine 检查它是否仍有 P。如果有——太好了,继续。如果 sysmon 拿走了它,goroutine 尝试获取任何空闲 P。如果根本没有空闲 P,它将自己放在 全局运行队列 上并等待被拾取。我们将在后续文章中更详细地介绍 sysmon。
到目前为止,我们看到了 goroutine 自愿阻塞——在 channel、互斥锁和系统调用上。但在后台,每次 goroutine 调用函数时都有更微妙的事情发生。
栈增长
goroutine 运行时还有另一件事会发生:它可能用完栈空间。Go goroutine 从微小的 2KB 栈开始,与 OS 线程不同,它们一开始不获得固定大小的栈。相反,编译器在大多数函数开头插入一个小检查,称为 栈增长序言。这个检查将当前栈指针与栈限制进行比较——如果没有足够的空间进行下一个函数调用,runtime 介入。
当那发生时,runtime 分配一个新的更大的栈(通常是两倍大小),复制旧栈内容,调整所有引用栈地址的指针,并释放旧栈。goroutine 然后在其新的更大的栈上继续运行,就像什么都没发生一样。这就是 Go 可以运行数百万 goroutine 的原因——它们从小开始,只在实际需要空间时才增长。
这个栈检查值得在这里提及,因为正如我们将在下一节看到的,调度器利用它进行协作抢占。
抢占
goroutine 也可能被非自愿停止。到目前为止我们看到的一切——阻塞在 channel、进行系统调用、完成——涉及 goroutine 合作。但如果 goroutine 从不让出呢?一个没有函数调用、channel 操作或内存分配的紧密计算循环永远不会给调度器机会在该 P 上运行其他东西。
Go 有两个答案。第一个是 协作抢占:编译器在大多数函数开头插入一个小检查,测试 goroutine 是否被要求让出。当 runtime 想要抢占 goroutine 时,它翻转一个标志,下一个函数调用触发检查并将控制权交还给调度器。这是廉价的——它重用已经存在的栈增长检查——但它只在函数调用处工作。
第二个是 异步抢占:对于卡在无函数调用的紧密循环中的 goroutine,runtime 直接向线程发送 OS 信号(Unix 上的 SIGURG)。信号处理器中断 goroutine,保存其状态,并让出给调度器。这是重锤——即使协作抢占无法工作时它也工作。
在这两种情况下,被抢占的 goroutine 直接转换到 _Grunnable 并回到运行队列上——它很快会再次获得运行机会。还有一个特殊的 _Gpreempted 状态,但那保留给 GC 或调试器需要通过 suspendG 完全暂停 goroutine 时。无论哪种情况,都是 sysmon 检测运行太长的 goroutine(超过 10ms)并触发抢占。我们将在系统监控器文章中探索细节。
死亡和回收
最后,goroutine 的函数返回。记得在创建期间 PC 被设置为指向 goexit 吗?所以返回落入 goexit0(),goroutine 处理自己的死亡。它将自己的状态更改为 _Gdead,清理其字段,丢弃 M 关联,并将自己放在 P 的空闲列表上。然后它调用 schedule() 为该 M 找到下一个 goroutine。
G 不被释放或垃圾回收。它坐在空闲列表上,包括栈,等待回收。这是一个关键优化——分配和设置新 G 比重新初始化死的 G 昂贵得多。这是故事完整循环的地方:新的 go 语句可能从空闲列表中拉出同一个 G,重新初始化它,并再次发送它经历整个旅程。
自助模式
贯穿所有这些阶段有一个模式:goroutine 总是自己做自己状态转换的工作。没有中央调度器线程拉线——goroutine 自己停放自己,添加自己到等待队列,清理自己,并调用调度器选择下一个 G。调度器真的只是一组 goroutine 对自己 调用的函数,使用 M 的 g0 栈来做记账。
大多数 goroutine 一生在 _Grunnable、_Grunning 和 _Gwaiting 之间弹跳——准备、运行、等待、准备、运行、等待——直到它们最终完成并返回 _Gdead。
有了数据结构和状态到位,让我们看看核心算法——驱动一切的循环。
调度循环
现在是调度器的心脏:schedule() 函数(在 src/runtime/proc.go 中)。这是在每个 M 上运行的循环,在 g0 栈上,它的工作很简单:找到一个可运行的 goroutine 并执行它。当 goroutine 停止运行(它阻塞、完成或被抢占),控制权返回到 schedule(),循环再次开始。
这是大致形状:
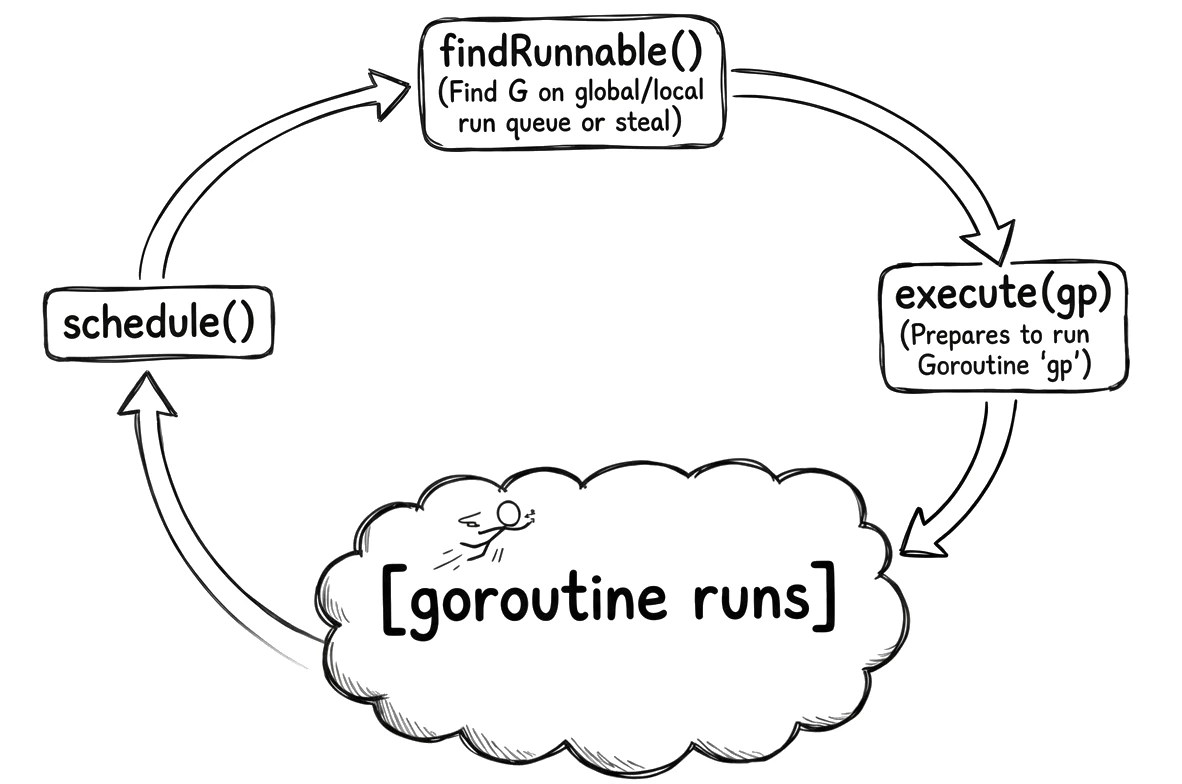
goroutine 运行直到它将控制权交还给调度器——自愿(通过在 channel 上阻塞、调用 runtime.Gosched() 等)或非自愿(通过抢占)。然后我们回到 schedule(),寻找下一个 goroutine。
schedule() 函数本身很简单。它检查几个特殊情况(这个 M 是否锁定到特定 goroutine?),然后调用 findRunnable() 获取下一个 goroutine。一旦有了,它调用 execute() 运行它。
有趣的部分是 findRunnable()——那是所有决策发生的地方。让我们分解它如何搜索工作。
寻找工作:搜索顺序
findRunnable()(在 src/runtime/proc.go 中)是回答"我接下来应该运行什么?“的函数。它按特定顺序搜索多个源,并继续寻找直到找到东西——如果确实没有要做的事情,它停放 M 睡眠直到工作出现,然后恢复搜索。
这是搜索顺序:
1. GC 和 Trace 工作
在寻找用户 goroutine 之前,调度器检查是否有 runtime 工作要做。如果 GC 活动并需要标记 worker,那优先。如果执行跟踪启用且其读取器 goroutine 准备就绪,那也优先。runtime 自己的需求优先。
2. 全局队列公平性检查
每 61 次 调度调用,调度器在查看本地队列之前从全局运行队列获取 单个 goroutine。为什么 61?它是一个质数,有助于避免同步模式,其中检查总是与同一个 goroutine 对齐。要点是防止饿死:如果 goroutine 不断被添加到本地队列,全局队列中的那些如果没有这个检查可能永远等待。
3. 本地运行队列
这是快速路径,大多数 goroutine 来自这里。调度器首先检查 runnext 槽位——一个优先级位置,持有最可能接下来运行的单个 goroutine。如果 runnext 设置,goroutine 获得它并 继承当前时间片,意味着它不重置调度滴答。这是对生产者 - 消费者模式的优化:如果 G1 在 channel 上发送并唤醒 G2,G2 进入 runnext 并立即运行,几乎像直接交接。
如果 runnext 为空,调度器从环形缓冲区获取——最多 256 个 goroutine 的无锁循环队列。只有拥有 M 写入此队列(单个生产者),所以常见情况不需要锁。
4. 全局运行队列(再次)
如果本地队列为空,检查全局队列。这次,不是只获取一个 goroutine,调度器获取 一批。这分摊了获取全局锁(sched.lock)的成本。一次锁获取,多个 goroutine。
5. 网络轮询
在诉诸偷窃之前,调度器检查 netpoller 查看是否有任何网络 I/O 准备就绪。如果任何 goroutine 被阻塞等待网络操作且那些操作现在完成,那些 goroutine 变为可运行。我们将在未来文章中讨论 netpoller 如何工作。
6. 工作偷窃
如果以上都为空,是时候偷窃了。调度器查看 其他 P 的本地队列 并获取它们一半的 goroutine。这是即使工作分布不均也保持所有核心忙碌的机制。
7. 最后手段:停放
如果确实没有任何地方有工作——没有本地工作、没有全局工作、没有网络 I/O、没有可偷窃的东西——M 释放其 P,将其放在空闲 P 列表上,并停放自己睡眠。它将在稍后新工作出现时被唤醒。
但那个"停放"决定并不像听起来那么直接。线程应该在工作用完时立即睡眠,还是应该停留一会儿以防有东西出现?
旋转线程
这里有一个微妙的平衡要把握。当线程用完工作——本地队列为空、没有可偷窃的东西——它应该立即睡眠吗?如果它这样做,而新工作一微秒后到达,没有人醒着拾取它。另一个线程必须从睡眠中唤醒,这花费时间。另一方面,如果太多空闲线程保持醒着燃烧 CPU 周期寻找不存在的工作,那是纯粹的浪费。
Go 的答案是 旋转线程。当 M 用完工作时,它不会立即停放。相反,它进入旋转状态——主动检查队列并尝试偷窃——短暂一段时间后才放弃并去睡眠。runtime 限制旋转器数量最多为 繁忙 P 数量的一半——所以在 8 核机器上有 6 个繁忙 P 时,最多 3 个线程可以同时旋转。足够响应,不会多到浪费 CPU。
硬币的另一面是新工作出现时——比如新 goroutine 被创建或 channel 解除阻塞。runtime 在这里甚至更保守:它只在有 零 旋转器时唤醒睡眠线程。如果已经有一个旋转线程在那里,它会拾取新工作。目标很简单:总是有人准备抓取新工作,但不要太多人。
所有这些机制——阻塞、解除阻塞、系统调用、抢占——涉及从一个 goroutine 切换到另一个。让我们看看那个切换实际花费多少。
上下文切换
让我们简短谈谈 goroutine 上下文切换期间发生什么,因为它是使整个系统快速的原因。
当调度器从一个 goroutine 切换到另一个时,它需要保存当前 goroutine 在哪里并恢复下一个离开的位置。好消息是 goroutine 的状态出奇地小。mcall() 汇编函数只保存 3 个值——栈指针、程序计数器和基址指针——到一个微小的 gobuf 结构体中。就是这样。为什么这么少?因为 goroutine 切换发生在函数调用边界,在这些点编译器已经按照正常调用约定将所有重要寄存器溢出到栈上。切换只需要保存足够的东西以再次找到栈。
gogo() 做相反的事情:它恢复那些保存的值并直接跳入 goroutine。一起,mcall() 和 gogo() 是每个自愿 goroutine 切换背后的机制。对于异步抢占(goroutine 在执行中被信号中断),完整的寄存器集必须保存——但那是例外,不是常见路径。
而且它很快。goroutine 上下文切换花费大约 50–100 纳秒——大约 200 个 CPU 周期。与 OS 线程上下文切换相比,后者涉及保存完整寄存器集并切换内核栈——那花费 1–2 微秒,慢 10 到 40 倍。这是 goroutine 比线程扩展性好得多的主要原因之一。
让我们总结我们学到的内容。
总结
Go 调度器使用 GMP 模型 将 goroutine 多路复用到 OS 线程:G(goroutine)是工作,M(OS 线程)提供执行,P(处理器)携带调度上下文——本地运行队列、内存缓存和高效运行 goroutine 所需的一切。全局 schedt 结构体通过共享状态将所有东西联系在一起,如全局运行队列、空闲列表和旋转线程计数。
我们跟随 goroutine 通过它的整个生命周期——从创建(可能时回收死 G),通过运行、阻塞(goroutine 自己停放)、系统调用(P 分离以便其他 goroutine 继续运行)、栈增长和抢占(协作和异步)。最后,goroutine 自己清理并回到空闲列表供重用。
schedule() 和 findRunnable() 中的调度循环驱动一切——检查本地队列、全局队列每 61 滴答公平性、netpoller,并在放弃之前从其他 P 偷窃。旋转线程 通过短暂保持醒着捕捉新工作保持系统响应,上下文切换 在 goroutine 之间只花费约 50–100 纳秒,因为涉及的状态量小。
如果你想自己探索实现,主要调度器代码在 src/runtime/proc.go 中,数据结构在 src/runtime/runtime2.go 中,汇编例程在 src/runtime/asm_*.s 中。
在下一篇文章中,我们将查看 垃圾回收器——它如何跟踪哪些对象仍然存活并回收其余部分,同时你的程序继续运行。