本文翻译自 Rethinking PID 1,版权归原作者所有。这是 systemd 作者发表于 2010 年的一篇文章,至今读来仍熠熠生辉。
如果你消息灵通,或者善于读懂言外之意,你可能已经知道这篇博文要讲什么了。但即便如此,你可能还是会觉得这个故事很有趣。所以,端起一杯咖啡,坐下来,读读接下来的内容吧。
这篇博文很长,所以虽然我只能推荐你读完整个故事,但这里有一句话总结:我们正在试验一个新的 init 系统,而且很有趣。
这是代码 故事是这样的:
进程标识符 1
在每个 Unix 系统上,都有一个进程拥有特殊的进程标识符 1。它在所有其他进程之前由内核启动,并且是所有那些没有其他父进程的进程的父进程。因此,它可以做很多其他进程不能做的事情。它也负责一些其他进程不负责的事情,比如在启动期间启动和维护用户空间。
从历史上看,在 Linux 上充当 PID 1 的软件是古老的 sysvinit 软件包,尽管它已经相当老旧了。人们提出了许多替代品,但只有一个真正流行起来:Upstart,它现在已经进入了所有主流发行版。
如前所述,init 系统的核心职责是启动用户空间。一个好的 init 系统会很快地完成这项工作。不幸的是,传统的 SysV init 系统并不是特别快。
为了实现快速高效的启动,有两件事至关重要:
- 启动更少的服务。
- 并且并行启动更多的服务。
这是什么意思?启动更少意味着启动更少的服务,或者将服务的启动推迟到实际需要时。有些服务我们知道迟早会需要(syslog、D-Bus 系统总线等),但对于许多其他服务来说,情况并非如此。例如,除非实际插入了蓝牙适配器或者应用程序想要与其 D-Bus 接口通信,否则 bluetoothd 不需要运行。打印系统也是如此:除非机器物理连接到打印机,或者应用程序想要打印某些东西,否则没有必要运行像 CUPS 这样的打印守护进程。Avahi:如果机器没有连接到网络,就没有必要运行 Avahi,除非某个应用程序想要使用其 API。甚至 SSH 也是如此:只要没有人想连接你的机器,就没有必要运行它,只要它在第一次连接时启动即可。(承认吧,在大多数可能正在监听 sshd 的机器上,有人可能每隔一两个月才连接一次。)
并行启动更多意味着,如果必须运行某些东西,我们不应该序列化它的启动(就像 sysvinit 那样),而是应该同时运行所有东西,这样可以最大限度地利用可用的 CPU 和磁盘 IO 带宽,从而最大限度地减少整体启动时间。
硬件和软件的动态变化
现代系统(尤其是通用操作系统)的配置和使用都具有高度的动态性:它们是移动的,不同的应用程序会启动和停止,不同的硬件会添加和移除。负责维护服务的 init 系统需要监听硬件和软件的变化。它需要根据运行程序或启用某些硬件的需要动态地启动(有时是停止)服务。
大多数试图并行化启动的当前系统仍然会同步所涉及的各种守护进程的启动:由于 Avahi 需要 D-Bus,因此首先启动 D-Bus,只有当 D-Bus 发出就绪信号时,Avahi 才会启动。其他服务也类似:livirtd 和 X11 需要 HAL(好吧,我这里考虑的是 Fedora 13 的服务,忽略 HAL 已经过时了),因此 HAL 首先启动,然后才启动 livirtd 和 X11。而 libvirtd 也需要 Avahi,所以它也等待 Avahi。它们都需要 syslog,所以它们都等待 Syslog 完全启动和初始化。等等。
并行化套接字服务
这种启动同步导致了启动过程中很大一部分的序列化。如果我们能够摆脱同步和序列化的成本,那岂不是很好?嗯,实际上我们可以。为此,我们需要了解守护进程之间到底需要什么,以及为什么它们的启动会延迟。对于传统的 Unix 守护进程,答案只有一个:它们等待另一个守护进程提供服务的套接字准备好接受连接。通常这是一个文件系统中的 AF_UNIX 套接字,但也可能是 AF_INET[6]。例如,D-Bus 的客户端等待 /var/run/dbus/system_bus_socket 可以连接,syslog 的客户端等待 /dev/log,CUPS 的客户端等待 /var/run/cups/cups.sock,NFS 挂载等待 /var/run/rpcbind.sock 和端口映射器的 IP 端口,等等。仔细想想,这实际上是它们唯一等待的事情!
现在,如果它们等待的就只有这些,如果我们能设法让这些套接字更早地可供连接,并且只实际等待这个而不是完整的守护进程启动,那么我们就可以加速整个启动过程并并行启动更多进程。那么,我们该怎么做呢?实际上在类 Unix 系统中相当容易:我们可以在实际启动守护进程之前创建监听套接字,然后在 exec() 期间将套接字传递给它。这样,我们就可以在 init 系统中一步创建所有守护进程的所有套接字,然后在第二步中一次性运行所有守护进程。如果一个服务需要另一个服务,而它还没有完全启动,那完全没问题:将会发生的是连接在提供服务的服务中排队,客户端可能会在该单个请求上阻塞。但只有那个客户端会阻塞,而且只在该单个请求上阻塞。此外,服务之间的依赖关系将不再需要配置以允许正确的并行启动:如果我们一次性启动所有套接字,而一个服务需要另一个服务,它可以确信它可以连接到它的套接字。
因为这是接下来内容的核心,让我换种说法再举个例子:如果你同时启动 syslog 和各种 syslog 客户端,在上面指出的方案中会发生的是,客户端的消息将被添加到 /dev/log 套接字缓冲区。只要该缓冲区没有满,客户端就不必以任何方式等待,可以立即继续启动。一旦 syslog 本身完成启动,它将取出所有消息并处理它们。另一个例子:我们同时启动 D-Bus 和几个客户端。如果发送了一个同步总线请求并因此期望一个答复,将会发生的是客户端将不得不阻塞,但是只有那个客户端会阻塞,并且只到 D-Bus 设法赶上并处理它为止。
基本上,内核套接字缓冲区帮助我们最大限度地实现并行化,而排序和同步由内核完成,无需用户空间的任何进一步管理!如果所有套接字在守护进程实际启动之前都可用,那么依赖管理也变得多余(或至少是次要的):如果一个守护进程需要另一个守护进程,它只需连接到它。如果另一个守护进程已经启动,这将立即成功。如果它还没有启动但在启动过程中,第一个守护进程甚至不必等待它,除非它发出同步请求。即使另一个守护进程根本没有运行,它也可以被自动生成。从第一个守护进程的角度来看,没有区别,因此依赖管理在很大程度上变得不必要或至少是次要的,所有这些都在最佳并行化和可选的按需加载中。最重要的是,这也更健壮,因为无论实际的守护进程是否可能暂时不可用(可能是由于崩溃),套接字都保持可用。事实上,你可以很容易地用这种方式编写一个守护进程,它可以运行、退出(或崩溃),然后再次运行并再次退出(等等),所有这些都不会让客户端注意到或丢失任何请求。
现在是暂停的好时机,去续杯咖啡,请放心,后面还有更有趣的内容。
但首先,让我们澄清几件事:这种逻辑是新的吗?不,当然不是。最著名的采用这种工作方式的系统是苹果的 launchd 系统:在 MacOS 上,所有守护进程的套接字监听都被抽离出来,由 launchd 完成。因此,服务本身都可以并行启动,并且不需要为它们配置依赖关系。这实际上是一个非常巧妙的设计,也是 MacOS 能够提供如此惊人启动时间的主要原因。我强烈推荐这个视频,其中 launchd 的工作人员解释了他们在做什么。不幸的是,这个想法从未真正在苹果阵营之外流行起来。
这个想法实际上比 launchd 还要古老。在 launchd 之前,古老的 inetd 的工作方式与此非常相似:套接字在一个守护进程中集中创建,该守护进程会在 exec() 期间启动实际的服务守护进程并传递套接字文件描述符。然而,inetd 的重点当然不是本地服务,而是互联网服务(尽管后来的重新实现也支持 AF_UNIX 套接字)。它也不是一个用于并行化启动的工具,甚至对于正确处理隐式依赖关系也没有用处。
对于 TCP 套接字,inetd 主要用于为每个传入连接生成一个新的守护进程实例。这意味着为每个连接生成并初始化一个新进程,这不是高性能服务器的良方。然而,从一开始 inetd 就支持另一种模式,即在第一个连接上生成一个守护进程,然后该单个实例将继续接受后续连接(这就是 inetd.conf 中 wait/nowait 选项的作用,不幸的是,这是一个文档特别糟糕的选项)。每个连接启动守护进程可能给 inetd 带来了速度慢的坏名声。但这并不完全公平。
并行化总线服务
Linux 上的现代守护进程倾向于通过 D-Bus 而不是普通的 AF_UNIX 套接字提供服务。现在的问题是,对于这些服务,我们是否可以应用与传统套接字服务相同的并行启动逻辑?是的,我们可以,D-Bus 已经为此提供了所有正确的钩子:使用总线激活,服务可以在第一次被访问时启动。总线激活还为我们提供了同时启动 D-Bus 服务提供者和消费者的最小化按需同步:如果我们想同时启动 Avahi 和 CUPS(旁注:CUPS 使用 Avahi 浏览 mDNS/DNS-SD 打印机),那么我们可以简单地同时运行它们,如果 CUPS 通过总线激活逻辑比 Avahi 更快,我们可以让 D-Bus 将请求排队,直到 Avahi 设法建立其服务名称。
所以,总而言之:基于套接字的服务激活和基于总线的服务激活共同使我们能够并行启动所有守护进程,而无需任何进一步的同步。激活还允许我们对服务进行延迟加载:如果一个服务很少使用,我们可以在有人第一次访问套接字或总线名称时加载它,而不是在启动时启动它。
如果这还不算好,那我真不知道什么才算好了!
并行化文件系统作业
如果你查看当前发行版启动过程的序列化图,你会发现除了守护进程启动之外还有更多的同步点:最突出的是与文件系统相关的作业:挂载、文件系统检查、配额。目前,在启动时,会花费大量时间空闲等待,直到 /etc/fstab 中列出的所有设备都出现在设备树中,然后进行文件系统检查、挂载、配额检查(如果启用)。只有在这一切完全完成后,我们才会继续启动实际的服务。
我们能改进这个吗?事实证明我们可以。Harald Hoyer 提出了使用古老的 autofs 系统的想法:
就像 connect() 调用表明一个服务对另一个服务感兴趣一样,open()(或类似的调用)表明一个服务对特定的文件或文件系统感兴趣。因此,为了提高并行化的程度,我们可以让那些应用程序只在它们正在寻找的文件系统尚未挂载并准备好时才等待:我们设置一个 autofs 挂载点,然后在我们的文件系统由于正常启动而完成 fsck 和配额检查后,我们用真正的挂载替换它。当文件系统还没有准备好时,访问将被内核排队,访问进程将被阻塞,但只有那个守护进程和那一次访问。通过这种方式,我们甚至可以在所有文件系统完全可用之前就开始启动我们的守护进程——而不会丢失任何文件,并最大限度地实现并行化。
并行化文件系统作业和服务作业对于 / 来说没有意义,毕竟服务二进制文件通常存储在那里。然而,对于像 /home 这样的文件系统,它们通常更大,甚至是加密的,可能是远程的,并且很少被通常的启动守护进程访问,这可以大大缩短启动时间。可能没有必要提及这一点,但虚拟文件系统,如 procfs 或 sysfs,绝不应该通过 autofs 挂载。
如果一些读者觉得在 init 系统中集成 autofs 有点脆弱甚至奇怪,甚至有点“疯狂”,我不会感到惊讶。然而,在广泛地尝试过之后,我可以告诉你,这实际上感觉很对。在这里使用 autofs 仅仅意味着我们可以创建一个挂载点,而不必立即提供支持的文件系统。因此,它实际上只是延迟了访问。如果一个应用程序试图访问一个 autofs 文件系统,而我们花了很长时间才用真正的文件系统替换它,它会挂起在一个可中断的睡眠中,这意味着你可以安全地取消它,例如通过 C-c。还要注意,在任何时候,如果挂载点最终无法挂载(也许是因为 fsck 失败),我们都可以告诉 autofs 返回一个干净的错误代码(比如 ENOENT)。所以,我想说的是,尽管将 autofs 集成到 init 系统中起初可能看起来很冒险,但我们的实验代码表明,这个想法在实践中出人意料地有效——如果它是出于正确的原因并以正确的方式完成的话。
还要注意,这些应该是直接的 autofs 挂载,这意味着从应用程序的角度来看,经典挂载点和基于 autofs 的挂载点之间几乎没有实际区别。
保持第一个用户 PID 小
我们可以从 MacOS 启动逻辑中学到的另一件事是,shell 脚本是邪恶的。Shell 既快又慢。它编写起来很快,但执行起来很慢。经典的 sysvinit 启动逻辑是围绕 shell 脚本建模的。无论是 /bin/bash 还是任何其他 shell(为了让 shell 脚本更快而编写的),最终这种方法注定是缓慢的。在我的系统上,/etc/init.d 中的脚本至少调用 grep 77 次。awk 被调用 92 次,cut 23 次,sed 74 次。每次调用这些命令(以及其他命令)时,都会生成一个进程,搜索库,设置一些启动项,如 i18n 等等。然后,在很少执行比琐碎的字符串操作更多的工作之后,进程再次终止。当然,这肯定非常慢。除了 shell,没有其他语言会这样做。最重要的是,shell 脚本也非常脆弱,并且会根据环境变量等因素急剧改变其行为,这些东西很难监督和控制。
所以,让我们在启动过程中摆脱 shell 脚本吧!在我们这样做之前,我们需要弄清楚它们目前实际用于什么:嗯,总的来说,大多数时候,它们做的事情实际上很无聊。大部分脚本都花在了服务的琐碎设置和拆卸上,应该用 C 语言重写,要么在单独的可执行文件中,要么移到守护进程本身中,要么干脆在 init 系统中完成。
我们不太可能在短期内完全摆脱系统启动过程中的 shell 脚本。用 C 语言重写它们需要时间,在少数情况下并没有真正的意义,而且有时 shell 脚本实在太方便了,无法不用。但我们当然可以降低它们的重要性。
衡量启动过程中 shell 脚本泛滥程度的一个好指标是系统完全启动后你可以启动的第一个进程的 PID 号。启动,登录,打开一个终端,然后输入 echo $$。在你的 Linux 系统上试试,然后和 MacOS 的结果比较一下!(提示,结果大概是这样的:Linux PID 1823;MacOS PID 154,在我们拥有的测试系统上测得。)
跟踪进程
一个启动和维护服务的系统的核心部分应该是进程监管:它应该监视服务。如果它们关闭了就重新启动它们。如果它们崩溃了,它应该收集关于它们的信息,并为管理员保留这些信息,并将这些信息与来自崩溃转储系统(如 abrt)和日志系统(如 syslog 或审计系统)的可用信息进行交叉链接。
它还应该能够完全关闭一个服务。这听起来可能很容易,但比你想象的要难。传统上,在 Unix 上,一个进行双重 fork 的进程可以逃脱其父进程的监督,而旧的父进程将无法了解新进程与它实际启动的进程之间的关系。一个例子:目前,一个行为不端的、已经双重 fork 的 CGI 脚本在您关闭 Apache 时不会被终止。此外,您甚至无法弄清楚它与 Apache 的关系,除非您知道它的名称和用途。
那么,我们如何才能跟踪进程,使它们无法逃脱监管,即使它们 fork 无数次,我们也能将它们作为一个整体来控制呢?
不同的人为此提出了不同的解决方案。我在这里不打算深入细节,但至少可以说,一些人研究和实现的基于 ptrace 或 netlink 连接器(一个内核接口,允许你在系统上任何进程 fork() 或 exit() 时获得一个 netlink 消息)的方法,被批评为丑陋且可扩展性不强。
那么我们能做些什么呢?嗯,内核很早就知道了控制组(又名“cgroups”)。基本上,它们允许创建进程组的层次结构。该层次结构直接暴露在一个虚拟文件系统中,因此很容易访问。组名基本上是该文件系统中的目录名。如果属于特定 cgroup 的进程 fork(),其子进程将成为同一组的成员。除非它具有特权并可以访问 cgroup 文件系统,否则它无法逃脱其组。最初,cgroups 被引入内核是为了容器的目的:某些内核子系统可以对某些组的资源强制执行限制,例如限制 CPU 或内存使用。传统的资源限制(由 setrlimit() 实现)是(大部分)每个进程的。另一方面,cgroups 允许您对整个进程组强制执行限制。cgroups 在直接容器用例之外也很有用,可以用来强制执行限制。例如,您可以使用它来限制 Apache 及其所有子进程可以使用的内存或 CPU 的总量。然后,一个行为不端的 CGI 脚本就不能再通过简单的 fork 来逃避您的 setrlimit() 资源控制了。
除了容器和资源限制强制执行之外,cgroups 对于跟踪守护进程也非常有用:cgroup 成员资格由子进程安全地继承,它们无法逃脱。有一个通知系统可用,以便在 cgroup 为空时通知监督进程。您可以通过读取 /proc/$PID/cgroup 来查找进程的 cgroups。因此,cgroups 是用于监管目的跟踪进程的绝佳选择。
控制进程执行环境
一个好的监管程序不仅应该监督和控制守护进程何时启动、结束或崩溃,还应该为其建立一个良好、最小化和安全的工作环境。
这意味着设置显而易见的进程参数,例如 setrlimit() 资源限制、用户/组 ID 或环境块,但这还不是全部。Linux 内核为用户和管理员提供了对进程的大量控制(其中一些目前很少使用)。对于每个进程,您可以设置 CPU 和 IO 调度程序控制、能力边界集、CPU 亲和性,当然还有带有附加限制的 cgroup 环境等等。
举个例子,使用 IOPRIO_CLASS_IDLE 的 ioprio_set() 是一个很好的方法,可以最大限度地减少 locate 的 updatedb 对系统交互性的影响。
最重要的是,某些高级控制可能非常有用,例如基于只读绑定挂载设置只读文件系统覆盖。这样,可以运行某些守护进程,使所有(或部分)文件系统对它们显示为只读,从而在每个写请求上返回 EROFS。因此,这可以用来锁定守护进程可以做的事情,类似于一个穷人的 SELinux 策略系统(但这当然不能取代 SELinux,请不要有任何坏主意)。
最后,日志记录是执行服务的重要组成部分:理想情况下,服务生成的每一位输出都应该被记录下来。因此,一个 init 系统应该从一开始就为它生成的守护进程提供日志记录,并将 stdout 和 stderr 连接到 syslog,或者在某些情况下甚至连接到 /dev/kmsg,在许多情况下,这可以成为 syslog 的一个非常有用的替代品(嵌入式开发人员,请注意!),尤其是在内核日志缓冲区被配置得非常大的时候。
关于 Upstart
首先,让我强调一下,我实际上很喜欢 Upstart 的代码,它的注释非常好,很容易理解。这当然是其他项目(包括我自己的项目)应该学习的东西。
话虽如此,我不能说我同意 Upstart 的总体方法。但首先,多谈谈这个项目:
Upstart 不与 sysvinit 共享代码,其功能是 sysvinit 的超集,并在一定程度上与众所周知的 SysV init 脚本兼容。它的主要特点是基于事件的方法:进程的启动和停止与系统中发生的“事件”绑定,其中“事件”可以是很多不同的事情,例如:网络接口可用或某个其他软件已启动。
Upstart 通过这些事件进行服务序列化:如果触发了 syslog-started 事件,这将被用作启动 D-Bus 的指示,因为它现在可以使用 Syslog。然后,当触发 dbus-started 时,NetworkManager 将被启动,因为它现在可以使用 D-Bus,依此类推。
可以说,通过这种方式,管理员或开发人员存在并理解的实际逻辑依赖树被转换并编码为事件和动作规则:管理员/开发人员意识到的每个逻辑“a 需要 b”规则都变成了“当 b 启动时启动 a”加上“当 b 停止时停止 a”。在某种程度上,这当然是一种简化:特别是对于 Upstart 本身的代码。然而,我认为这种简化实际上是有害的。首先,逻辑依赖系统并没有消失,编写 Upstart 文件的人现在必须手动将依赖关系转换为这些事件/动作规则(实际上,每个依赖关系有两条规则)。因此,用户必须手动将依赖关系转换为简单的事件/动作规则,而不是让计算机根据依赖关系来决定该做什么。此外,由于依赖关系信息从未被编码,因此在运行时不可用,这实际上意味着试图找出为什么发生某事(即为什么在 b 启动时启动 a)的管理员没有机会找到答案。
此外,事件逻辑将所有依赖关系颠倒过来,从脚到头。它不是最小化工作量(正如这篇博文开头指出的,一个好的 init 系统应该关注这一点),而是最大化操作期间要做的工作量。换句话说,它不是有一个明确的目标,只做真正需要做的事情来达到目标,而是走一步,然后在完成之后,它会做所有可能跟随它的步骤。
或者说得更简单一点:用户刚刚启动了 D-Bus 绝不意味着 NetworkManager 也应该启动(但这是 Upstart 会做的)。恰恰相反:当用户请求 NetworkManager 时,这绝对是 D-Bus 也应该启动的指示(这当然是大多数用户的期望,对吧?)。
一个好的 init 系统应该只启动需要的东西,并且是按需启动。要么是懒加载,要么是并行化并提前启动。然而,它不应该启动超过必要的东西,特别是不要启动所有可能使用该服务的已安装的东西。
最后,我看不出事件逻辑的实际用处。在我看来,Upstart 中暴露的大多数事件实际上都不是瞬时的,而是有持续时间的:一个服务启动、正在运行和停止。一个设备插入、可用,然后再次拔出。一个挂载点正在挂载、已完全挂载或正在卸载。一个电源插头插入、系统在交流电下运行,然后电源插头被拔掉。一个 init 系统或进程管理器应该处理的事件中,只有少数是瞬时的,大多数是开始、条件和停止的元组。这些信息在 Upstart 中再次不可用,因为它专注于单个事件,而忽略了持久的依赖关系。
现在,我知道我上面指出的一些问题在某种程度上被 Upstart 最近的一些变化所缓解,特别是基于条件的语法,例如 Upstart 规则文件中的 start on (local-filesystems and net-device-up IFACE=lo)。然而,在我看来,这主要是在试图修复一个核心设计有缺陷的系统。
除此之外,Upstart 在监管守护进程方面做得还不错,尽管有些选择可能值得商榷(见上文),而且肯定有很多错失的机会(也见上文)。
除了 sysvinit、Upstart 和 launchd 之外,还有其他 init 系统。它们中的大多数提供的实质性内容比 Upstart 或 sysvinit 多不了多少。另一个最有趣的竞争者是 Solaris SMF,它支持服务之间的适当依赖关系。然而,在许多方面,它过于复杂,而且,可以说,有点学术化,因为它过度使用 XML 和为已知事物使用新术语。它还与 Solaris 特定的功能(如契约系统)紧密相连。
综合起来:systemd
嗯,现在又是一个暂停的好时机,因为在我希望上面已经解释了我认为一个好的 PID 1 应该做什么以及当前最常用的系统做什么之后,我们现在要进入正题了。所以,再去续杯咖啡吧。这会是值得的。
你可能已经猜到了:我上面提出的理想 init 系统的要求和功能现在实际上已经可用了,在一个(仍处于实验阶段)名为 systemd 的 init 系统中,我在此宣布它。再次,这是代码。 以下是其功能及其背后原理的简要介绍:
systemd 启动并监督整个系统(因此得名……)。它实现了上面指出的所有功能以及更多功能。它基于 units 的概念。单元有一个名称和一个类型。由于它们的配置通常直接从文件系统加载,因此这些单元名称实际上是文件名。例如:一个单元 avahi.service 是从同名的配置文件中读取的,当然也可以是封装 Avahi 守护进程的单元。有几种类型的单元:
service:这是最明显的一种单元:可以启动、停止、重启、重新加载的守护进程。为了与 SysV 兼容,我们不仅支持我们自己的服务配置文件,还能够读取经典的 SysV init 脚本,特别是如果存在 LSB 头,我们会解析它。因此,/etc/init.d不过是另一个配置来源而已。socket:此单元封装了文件系统或互联网上的套接字。我们目前支持 AF_INET、AF_INET6、AF_UNIX 类型的流、数据报和顺序数据包套接字。我们还支持经典的 FIFO 作为传输方式。每个socket单元都有一个匹配的service单元,如果在套接字或 FIFO 上有第一个连接进来,该服务单元就会启动。例如:nscd.socket在有传入连接时启动nscd.service。device:此单元封装了 Linux 设备树中的一个设备。如果一个设备通过 udev 规则被标记为此,它将在 systemd 中作为device单元公开。用udev设置的属性可以用作配置源来设置设备单元的依赖关系。mount:此单元封装了文件系统层次结构中的一个挂载点。systemd 监视所有挂载点的来去,也可以用来挂载或卸载挂载点。/etc/fstab在这里用作这些挂载点的附加配置源,类似于 SysV init 脚本如何用作service单元的附加配置源。automount:此单元类型封装了文件系统层次结构中的一个自动挂载点。每个automount单元都有一个匹配的mount单元,一旦访问自动挂载目录,该挂载单元就会启动(即挂载)。target:此单元类型用于对单元进行逻辑分组:它本身实际上不做任何事情,只是引用其他单元,从而可以一起控制它们。例如:multi-user.target,它基本上扮演着经典 SysV 系统上运行级别 5 的角色,或者bluetooth.target,它在蓝牙适配器可用时被请求,并且只是引入了否则不需要启动的蓝牙相关服务:bluetoothd和obexd等。snapshot:与target单元类似,快照本身实际上不做任何事情,其唯一目的是引用其他单元。快照可用于保存/回滚 init 系统所有服务和单元的状态。它主要有两个预期的用例:允许用户临时进入特定状态,例如“紧急 Shell”,终止当前服务,并提供一种简单的方法返回到之前的状态,重新启动所有被临时关闭的服务。以及简化对系统挂起的支持:仍然有许多服务无法正确处理系统挂起,在挂起之前关闭它们,然后在之后恢复它们通常是一个更好的主意。
所有这些单元之间都可以有依赖关系(包括正向和负向,即“Requires”和“Conflicts”):一个设备可以依赖于一个服务,这意味着一旦一个设备可用,某个服务就会启动。挂载点会隐式地依赖于它们所挂载的设备。挂载点还会隐式地依赖于作为其前缀的挂载点(例如,挂载 /home/lennart 会隐式地为 /home 的挂载添加一个依赖关系),等等。
其他功能简述:
- 对于每个生成的进程,您可以控制:环境、资源限制、工作和根目录、umask、OOM killer 调整、nice 级别、IO 类别和优先级、CPU 策略和优先级、CPU 亲和性、定时器松弛、用户 ID、组 ID、补充组 ID、可读/可写/不可访问目录、共享/私有/从属挂载标志、能力/边界集、安全位、fork 的 CPU 调度程序重置、私有
/tmp命名空间、各种子系统的 cgroup 控制。此外,您可以轻松地将服务的 stdin/stdout/stderr 连接到 syslog、/dev/kmsg、任意 TTY。如果连接到 TTY 以进行输入,systemd 将确保进程获得独占访问权限,可选择等待或强制执行。 - 每个执行的进程都会获得自己的 cgroup(目前默认在调试子系统中,因为该子系统没有其他用途,并且除了最基本的进程分组之外没有做太多事情),并且很容易配置 systemd 将服务放置在已在外部配置的 cgroup 中,例如通过 libcgroups 实用程序。
- 本机配置文件使用一种与众所周知的
.desktop文件非常相似的语法。这是一种简单的语法,许多软件框架中已经存在其解析器。此外,这使我们能够依赖现有的 i18n 工具来处理服务描述等。管理员和开发人员不需要学习新的语法。 - 如前所述,我们提供与 SysV init 脚本的兼容性。如果 LSB 和 Red Hat chkconfig 头可用,我们会利用它们。如果不可用,我们会尽力利用其他可用信息,例如
/etc/rc.d中的启动优先级。这些 init 脚本仅被视为不同的配置来源,因此可以轻松升级到适当的 systemd 服务。我们可以选择性地读取服务的经典 PID 文件以识别守护进程的主 pid。请注意,我们利用 LSB init 脚本头中的依赖信息,并将其转换为本机 systemd 依赖。旁注:Upstart 无法获取和利用该信息。因此,在主要使用 LSB SysV init 脚本的普通 Upstart 系统上启动不会并行化,而运行 systemd 的类似系统则会。事实上,对于 Upstart,所有 SysV 脚本共同构成一个执行的作业,它们不被单独处理,这与 systemd 形成对比,在 systemd 中,SysV init 脚本只是另一种配置来源,并且像任何其他本机 systemd 服务一样被单独处理和控制。 - 同样,我们读取现有的
/etc/fstab配置文件,并将其视为另一个配置来源。使用comment=fstab 选项,您甚至可以将/etc/fstab条目标记为systemd控制的自动挂载点。 - 如果同一个单元在多个配置源中配置(例如,
/etc/systemd/system/avahi.service和/etc/init.d/avahi都存在),则本机配置将始终优先,旧格式将被忽略,从而允许轻松的升级路径,并且软件包可以同时携带 SysV init 脚本和 systemd 服务文件一段时间。 - 我们支持一个简单的模板/实例机制。例如:我们只有一个
getty@.service文件,而不是为六个 getty 准备六个配置文件,该文件被实例化为getty@tty2.service等。接口部分甚至可以被依赖表达式继承,即很容易编码一个服务dhcpcd@eth0.service引入avahi-autoipd@eth0.service,同时将eth0字符串保留为通配符。 - 对于套接字激活,我们支持与传统 inetd 模式的完全兼容性,以及一个非常简单的模式,该模式试图模仿 launchd 套接字激活,并推荐用于新服务。inetd 模式只允许将一个套接字传递给启动的守护进程,而本机模式支持传递任意数量的文件描述符。我们还支持每个连接一个实例,以及所有连接一个实例的模式。在前一种模式中,我们根据连接参数命名守护进程将启动的 cgroup,并为此利用上面提到的模板逻辑。例如:
sshd.socket可能会生成服务sshd@192.168.0.1-4711-192.168.0.2-22.service,其 cgroup 为sshd@.service/192.168.0.1-4711-192.168.0.2-22(即 IP 地址和端口号用于实例名称。对于 AF_UNIX 套接字,我们使用连接客户端的 PID 和用户 ID)。这为管理员提供了一种很好的方式来识别守护进程的各种实例并单独控制它们的运行时。本机套接字传递模式在应用程序中非常容易实现:如果设置了$LISTEN_FDS,它包含传递的套接字数量,守护进程将按照.service文件中列出的顺序找到它们,从文件描述符 3 开始(一个写得好的守护进程也可以使用fstat()和getsockname()来识别套接字,以防它收到多个)。此外,我们将$LISTEN_PID设置为应接收 fds 的守护进程的 PID,因为环境变量通常由子进程继承,因此可能会混淆链中更下游的进程。尽管这种套接字传递逻辑在守护进程中实现起来非常简单,但我们将提供一个 BSD 许可的参考实现,以展示如何做到这一点。我们已经将一些现有的守护进程移植到了这个新方案中。 - 我们在一定程度上提供与
/dev/initctl的兼容性。这种兼容性实际上是通过一个 FIFO 激活的服务实现的,该服务只是将这些旧的请求转换为 D-Bus 请求。这实际上意味着来自 Upstart 和sysvinit的旧shutdown、poweroff和类似命令可以继续与 systemd 一起工作。 - 我们还提供与
utmp和wtmp的兼容性。考虑到utmp和wtmp的陈旧程度,这种兼容性甚至可能超出了健康的范围。 systemd支持单元之间的几种依赖关系。After/Before可用于确定单元激活的顺序。它与Requires和Wants完全正交,后者表示正向需求依赖,可以是强制性的,也可以是可选的。然后,还有Conflicts,它表示负向需求依赖。最后,还有三种其他不太常用的依赖类型。systemd有一个最小的事务系统。意思是:如果请求启动或关闭一个单元,我们会将它及其所有依赖项添加到一个临时的transaction中。然后,我们将验证事务是否一致(即所有单元通过After/Before的排序是否无环)。如果不是,systemd 将尝试修复它,并从事务中删除可能导致循环的非必要作业。此外,systemd 会尝试抑制事务中会停止正在运行的服务的非必要作业。非必要作业是那些原始请求没有直接包含但被Wants类型的依赖项引入的作业。最后,我们检查事务的作业是否与已经排队的作业相矛盾,如果相矛盾,则可以选择中止事务。如果一切顺利,并且事务是一致的并且其影响最小化,它将与所有已经存在的作业合并并添加到运行队列中。这实际上意味着在执行请求的操作之前,我们将验证它是否有意义,如果可能则修复它,并且只有在它真的无法工作时才会失败。- 我们记录我们生成和监督的每个进程的启动/退出时间以及 PID 和退出状态。这些数据可用于将守护进程与其在 abrtd、auditd 和 syslog 中的数据进行交叉链接。想象一个 UI,它会为您突出显示崩溃的守护进程,并允许您轻松导航到 syslog、abrt 和 auditd 的相应 UI,这些 UI 将显示在特定运行中为此守护进程生成的数据。
- 我们支持随时重新执行 init 进程本身。守护进程状态在重新执行之前被序列化,之后被反序列化。这样,我们提供了一种简单的方法来促进 init 系统升级以及从 initrd 守护进程到最终守护进程的切换。打开的套接字和 autofs 挂载被正确地序列化,以便它们始终保持可连接状态,以至于客户端甚至不会注意到 init 系统已经重新执行了自己。此外,服务状态的很大一部分无论如何都编码在 cgroup 虚拟文件系统中,这一事实甚至允许我们在没有访问序列化数据的情况下恢复执行。重新执行代码路径实际上与 init 系统配置重新加载代码路径大部分相同,这保证了重新执行(可能触发得更少)得到与重新加载(可能更常见)类似的测试。
- 为了开始从启动过程中移除 shell 脚本的工作,我们用 C 语言重新编写了部分基本系统设置,并将其直接移入 systemd。其中包括挂载 API 文件系统(即虚拟文件系统,如
/proc、/sys和/dev)和设置主机名。 - 服务器状态可通过 D-Bus 进行内省和控制。这还不完整,但相当广泛。
- 虽然我们想强调基于套接字和基于总线名称的激活,因此我们支持套接字和服务之间的依赖关系,但我们也支持传统的服务间依赖关系。我们支持多种方式让这样的服务发出就绪信号:通过 fork 并让启动进程退出(即传统的
daemonize()行为),以及通过监视总线直到出现配置的服务名称。 - 有一个交互模式,每次 systemd 生成一个进程时都会要求确认。您可以通过在内核命令行上传递
systemd.confirm_spawn=1来启用它。 - 使用
systemd.default=内核命令行参数,您可以指定 systemd 在启动时应启动哪个单元。通常您会在这里指定类似multi-user.target的东西,但另一个选择甚至可以是一个单一的服务而不是一个目标,例如,我们开箱即用地提供了一个emergency.service服务,它的用处类似于init=/bin/bash,但它的优点是实际上运行了 init 系统,因此提供了从紧急 shell 启动整个系统的选项。 - 有一个最小的 UI,允许您启动/停止/内省服务。它远未完成,但作为调试工具很有用。它是用 Vala(耶!)编写的,名为
systemadm。
应该注意的是,systemd 使用了许多 Linux 特有的功能,并且不局限于 POSIX。这解锁了许多为可移植到其他操作系统而设计的系统无法提供的功能。
状态
上面列出的所有功能都已实现。目前,systemd 已经可以作为 Upstart 和 sysvinit 的直接替代品(至少只要还没有太多原生的 upstart 服务。谢天谢地,大多数发行版还没有太多原生的 Upstart 服务。)
然而,测试很少,我们的版本号目前是令人印象深刻的 0。如果您在当前状态下运行它,请做好出现问题的准备。话虽如此,总的来说它应该相当稳定,我们中的一些人已经用 systemd 启动了他们的常规开发系统(而不仅仅是虚拟机)。您的体验可能会有所不同,特别是如果您在我们开发人员不使用的发行版上尝试它。
未来走向何方?
上面描述的功能集当然已经很全面了。然而,我们还有一些事情要做。我不太喜欢过多地谈论宏伟的计划,但这里简要概述一下我们将朝着哪个方向努力:
我们希望至少再增加两种单元类型:swap 将用于控制交换设备,就像我们已经控制挂载一样,即具有对它们从中激活的设备树设备的自动依赖关系等。timer 将提供类似于 cron 的功能,即根据时间事件启动服务,重点是单调时钟和挂钟/日历事件。(即“上次运行后 5 小时启动”以及“每周一早上 5 点启动”)
然而,更重要的是,我们还计划试验 systemd,不仅用于优化启动时间,还使其成为理想的会话管理器,以取代(或可能只是增强)gnome-session、kdeinit 和类似的守护进程。会话管理器和 init 系统的问题集非常相似:快速启动至关重要,而进程监管是重点。因此,为这两种用途使用相同的代码是显而易见的。苹果认识到了这一点,并用 launchd 做到了这一点。我们也应该这样做:基于套接字和总线的激活和并行化是会话服务和系统服务都可以同样受益的东西。
我可能应该指出,所有这三个功能在当前代码库中都已经部分可用,但尚未完成。例如,您已经可以作为普通用户正常运行 systemd,它会检测到以这种方式运行,并且从一开始就支持此模式,并且是核心功能。(这对于调试也非常有用!即使系统没有转换为使用 systemd 启动,这也能正常工作。)
然而,在完成这项工作之前,我们可能应该在内核和其他地方修复一些问题:我们需要来自内核的交换状态更改通知,类似于我们已经可以订阅挂载更改的方式;我们希望在 CLOCK_REALTIME 相对于 CLOCK_MONOTONIC 跳转时收到通知;我们希望允许普通进程获得一些类似 init 的能力;我们需要一个定义明确的地方来放置用户套接字。这些问题对于 systemd 来说都不是真正必要的,但它们肯定会改善情况。
你想看它实际运行吗?
目前还没有 tarball 版本,但从我们的仓库中检出代码应该很简单。此外,为了让您有个开始,这里有一个包含单元配置文件的 tarball,它允许一个未经修改的 Fedora 13 系统与 systemd 一起工作。我们目前没有 RPM 包提供给您。
一个更简单的方法是下载这个为 systemd 准备的 Fedora 13 qemu 镜像。在 grub 菜单中,您可以选择使用 Upstart 还是 systemd 启动系统。请注意,该系统仅经过最低限度的修改。服务信息完全从现有的 SysV init 脚本中读取。因此,它不会利用上面指出的完整的基于套接字和总线的并行化,但是它会解释 LSB 头中的并行化提示,因此比 Upstart 系统启动得更快,而 Upstart 系统目前在 Fedora 中没有使用任何并行化。该镜像配置为在串行控制台上输出调试信息,并将其写入内核日志缓冲区(您可以使用 dmesg 访问)。您可能需要运行配置了虚拟串行终端的 qemu。所有密码都设置为 systemd。
比下载和启动 qemu 镜像更简单的是看漂亮的屏幕截图。由于 init 系统通常隐藏在用户界面之下,因此必须使用 systemadm 和 ps 的一些截图:
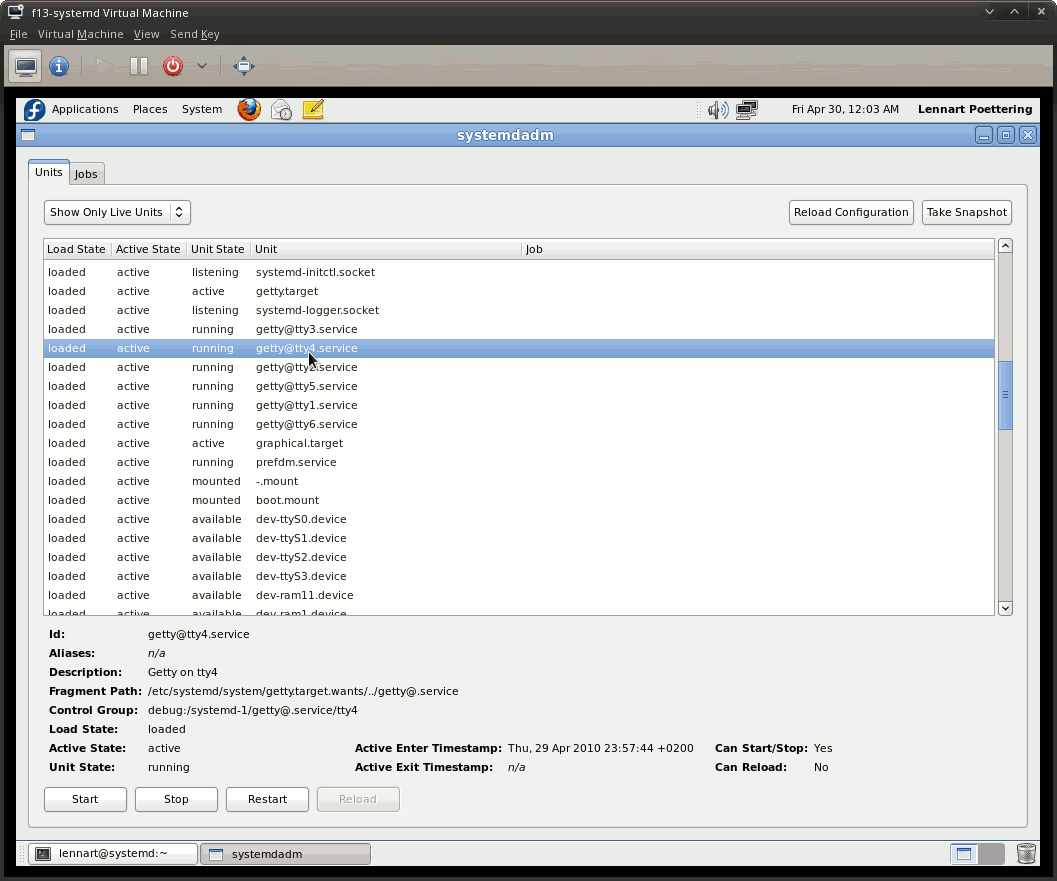
这是 systemadm 显示所有已加载的单元,并提供了其中一个 getty 实例的更详细信息。
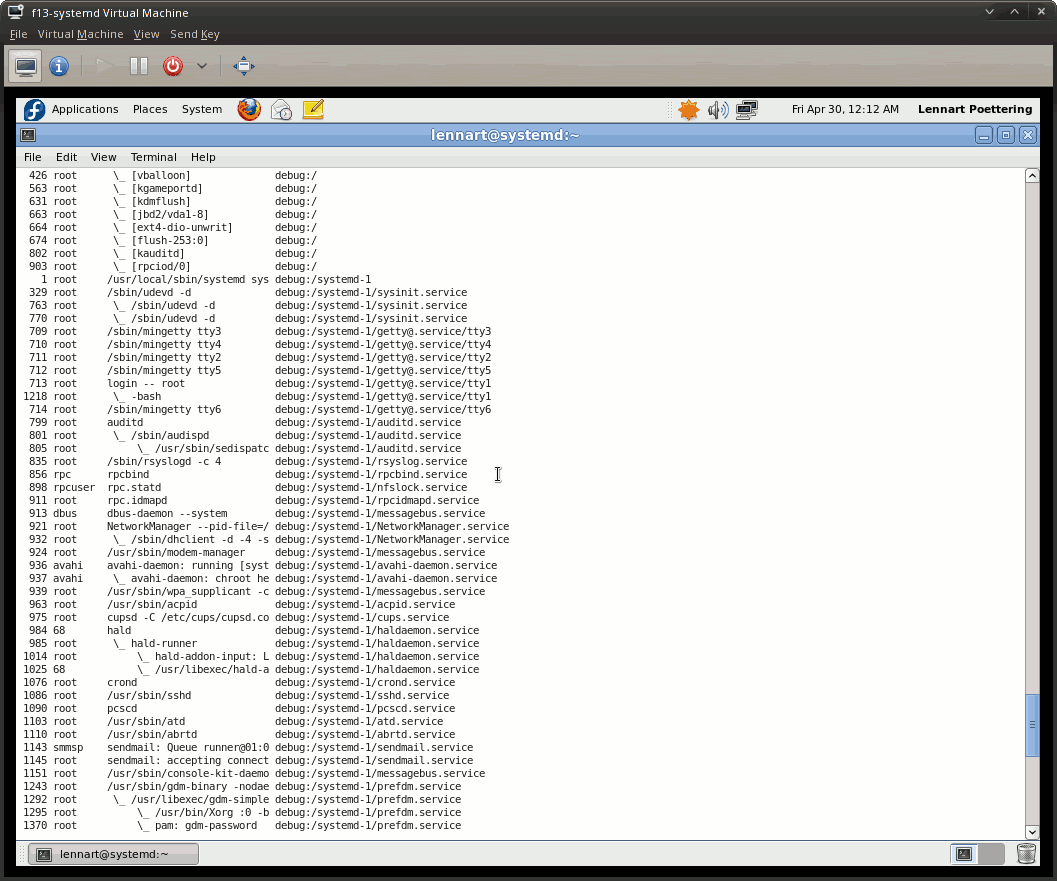
这是 ps xaf -eo pid,user,args,cgroup 输出的摘录,显示了进程如何整齐地分类到其服务的 cgroup 中。(第四列是 cgroup,“debug:”前缀显示是因为我们为 systemd 使用了调试 cgroup 控制器,如前所述。这只是暂时的。)
请注意,这两个屏幕截图都显示了一个仅经过最低限度修改的 Fedora 13 Live CD 安装,其中服务完全从现有的 SysV init 脚本加载。因此,这没有对任何现有服务使用套接字或总线激活。
抱歉,目前没有启动图表或启动时间的硬数据。一旦我们完全并行化了默认 Fedora 安装中的所有服务,我们就会发布这些数据。届时,我们欢迎您对 systemd 方法进行基准测试,我们也将提供我们自己的基准测试数据。
嗯,想必大家都会一直追问我这件事,所以这里有两个数字告诉大家。然而,它们完全不科学,因为它们是在虚拟机(单 CPU)上测量的,并且是使用我手表上的秒表计时的。使用 Upstart 启动 Fedora 13 需要 27 秒,而使用 systemd 我们达到了 24 秒(从 grub 到 gdm,相同的系统,相同的设置,两次启动中较短的值,一次紧接着另一次)。然而请注意,这只显示了通过使用从 init 脚本头解析的 LSB 依赖信息进行并行化所达到的加速效果。此未使用基于套接字或总线的激活,因此这些数字不适合评估上面指出的想法。此外,systemd 在串行控制台上设置为调试详细级别。所以再次强调,这个基准数据几乎没有任何价值。
编写守护进程
一个理想的与 systemd 一起使用的守护进程在一些方面与传统做法不同。稍后,我们将发布一个更长的指南,解释并建议如何为这个 systemd 编写守护进程。基本上,对于守护进程开发者来说,事情变得更简单了:
- 我们要求守护进程编写者不要在他们的进程中 fork 甚至 double fork,而是从 systemd 为您启动的初始进程中运行他们的事件循环。另外,不要调用
setsid()。 - 不要在守护进程本身中降低用户权限,将此留给 systemd 并在 systemd 服务配置文件中进行配置。(这里有例外。例如,对于某些守护进程,在需要提升权限的初始化阶段之后,在守护进程代码内部降低权限是有充分理由的。)
- 不要写 PID 文件
- 在总线上获取一个名称
- 您可以依赖 systemd 进行日志记录,欢迎您将需要记录的任何内容记录到 stderr。
- 让 systemd 为您创建和监视套接字,以便套接字激活能够工作。因此,如上所述解释
$LISTEN_FDS和$LISTEN_PID。 - 使用 SIGTERM 请求关闭您的守护进程。
上面的列表与苹果为与 launchd 兼容的守护进程推荐的列表非常相似。扩展已经支持 launchd 激活的守护进程以支持 systemd 激活应该很容易。
请注意,systemd 也完美支持非此风格编写的守护进程,这已经是出于兼容性原因(launchd 对此的支持有限)。如前所述,这甚至扩展到现有的能够使用 inetd 的守护进程,这些守护进程可以未经修改地用于 systemd 的套接字激活。
所以,是的,如果 systemd 在我们的实验中证明了自己并被发行版采用,那么将至少那些默认启动的服务移植到使用基于套接字或总线的激活是有意义的。我们已经编写了概念验证补丁,并且移植过程非常简单。此外,我们可以在一定程度上利用已经为 launchd 完成的工作。此外,添加对基于套接字的激活的支持并不会使服务与非 systemd 系统不兼容。
常见问题
谁是幕后推手?
嗯,当前的代码库主要是我,Lennart Poettering(红帽)的工作。然而,其所有细节的设计是 Kay Sievers(Novell)和我密切合作的结果。其他参与者包括 Harald Hoyer(红帽)、Dhaval Giani(前 IBM),以及来自英特尔、SUSE 和诺基亚等公司的其他一些人。
这是红帽的项目吗?
不,这是我个人的业余项目。另外,让我强调一下:这里反映的观点是我个人的。它们不代表我的雇主、罗纳德·麦当劳或任何其他人的观点。
这会进入 Fedora 吗?
如果我们的实验证明这种方法可行,并且 Fedora 社区的讨论表明支持这种方法,那么是的,我们肯定会努力将其引入 Fedora。
这会进入 OpenSUSE 吗?
Kay 正在努力,所以这里也适用与 Fedora 类似的情况。
这会进入 Debian/Gentoo/Mandriva/MeeGo/Ubuntu/[在此处插入您最喜欢的发行版]吗?
这取决于他们。我们当然欢迎他们的兴趣,并乐于帮助整合。
你为什么不直接把它添加到 Upstart,为什么要发明新东西?
嗯,上面关于 Upstart 的部分的重点是表明,我们认为 Upstart 的核心设计是有缺陷的。如果现有的解决方案在其核心上看起来有缺陷,那么从头开始就显得很自然了。然而,请注意,我们在其他方面从 Upstart 的代码库中获得了很多灵感。
如果你那么喜欢 Apple launchd,为什么不采用它呢?
launchd 是一项伟大的发明,但我不相信它能很好地融入 Linux,也不相信它适合像 Linux 这样具有巨大可扩展性和灵活性以适应众多目的和用途的系统。
这是一个 NIH 项目吗?
嗯,我希望我在上面的文字中已经解释了为什么我们提出了新的东西,而不是建立在 Upstart 或 launchd 之上。我们提出 systemd 是出于技术原因,而不是政治原因。
别忘了,是 Upstart 包含了一个名为 NIH 的库(它有点像 glib 的重新实现)——而不是 systemd!
这能在[在此处插入非 Linux 操作系统]上运行吗?
不太可能。如前所述,systemd 使用了许多 Linux 特定的 API(例如 epoll、signalfd、libudev、cgroups 等等),将其移植到其他操作系统对我们来说意义不大。此外,我们这些参与者也不太可能对合并可能移植到其他平台的代码并处理由此带来的限制感兴趣。话虽如此,git 对分支和变基的支持相当好,以防有人真的想进行移植。
实际上,可移植性甚至比其他操作系统更受限制:我们需要非常新的 Linux 内核、glibc、libcgroup 和 libudev。抱歉,不支持非最新的 Linux 系统。
如果有人想为其他操作系统实现类似的东西,首选的合作模式可能是我们帮助您确定哪些接口可以与您的系统共享,以便守护进程编写者更容易地同时支持 systemd 和您的 systemd 对应物。可能,重点应该是共享接口,而不是代码。
我听说[在此处填写一个:Gentoo 启动系统、initng、Solaris SMF、runit、uxlaunch 等]是一个很棒的 init 系统,并且也支持并行启动,那为什么不采用它呢?
嗯,在我们开始这个项目之前,我们实际上仔细研究了各种系统,但没有一个能做到我们为 systemd 设想的那样(当然,launchd 除外)。如果你看不出这一点,那么请再读一遍我上面写的内容。
贡献
我们对补丁和帮助非常感兴趣。每个自由软件项目只能从最广泛的外部贡献中受益,这应该是常识。对于操作系统的核心部分,例如 init 系统,尤其如此。我们重视您的贡献,因此不要求版权转让(与 Canonical/Upstart 非常不同!)。而且,我们使用 git,大家最喜欢的版本控制系统,耶!
我们特别希望有人能帮助我们在 Fedora 和 OpenSUSE 之外的其他发行版上运行 systemd。(嘿,有没有来自 Debian、Gentoo、Mandriva、MeeGo 的人想找点事做?)但除此之外,我们热衷于吸引各个层面的贡献者:我们欢迎 C 语言黑客、打包者,以及有兴趣编写文档或贡献徽标的人。
社区
目前我们只有一个源代码仓库和一个 IRC 频道(Freenode 上的“#systemd”)。没有邮件列表、网站或错误跟踪系统。我们可能很快会在 freedesktop.org 上建立一些东西。如果您有任何问题或想以其他方式联系我们,我们邀请您加入我们的 IRC!
更新: 我们的 GIT 仓库已经迁移。