本文翻译自 Sporks of AGI,版权归原作者所有。
训练大型模型真的很困难,随着模型变得越来越大并扩展到新的领域,这只会变得更加困难。大语言模型(LLMs)使用大量的文本数据,而视觉-语言模型(VLMs)需要包含文本和图像的数据,机器人技术中的视觉-语言-动作(VLA)模型需要大量机器人在现实世界中执行真实任务的数据。这对智能体的冲击尤其严重:无论你是想控制现实世界的机器人,还是想在网络上采取行动来满足用户请求,带有动作标签的真实世界交互数据都无法像从网络上获取文本和图像那样廉价地获得。难怪研究人员一直在试图找到一种方法来用次优选择来替代真实数据中的观察和动作,试图获得两全其美的效果:在巨大数据集上训练巨大模型所带来的力量和泛化能力,而成本却比在领域内数据上训练基础模型的标准方法要低得多。
次优选择
虽然真实的现实世界数据一直是视觉感知和自然语言处理的首选,但当涉及到智能体——特别是机器人智能体(例如 VLA)时,有一种无法抗拒的冲动,想要弄清楚如何使用其他东西,某种代理数据,这种数据可以廉价获得,但仍然提供我们期望从基础模型中获得的广泛泛化能力。我在这篇文章中将重点关注机器人技术,但其他领域也遵循类似的脚本,只是参与者不同。仿真是一个经典选择。如果我们能够弄清楚如何在"矩阵"中或在一个非常好的视频游戏中训练机器人,也许我们就可以避免对真实数据的需求。其他选择包括使用人类的视频,可能从网络上抓取,或者使用手持的类似夹具的设备,人们可以用这些设备录制自己以更机器人化的方式执行任务的视频。虽然这一领域已经有了大量令人兴奋和惊人创新的研究,但我们可以冒着画漫画的风险,将其描述如下:手动定义廉价的代理域和真实世界机器人系统之间的映射或对应关系,然后利用这种对应关系来使用这些廉价数据,而不是昂贵但具有代表性的域内数据(即来自目标域中真实机器人的数据)。每种广泛研究的避免真实世界机器人数据需求的方法都基于某种此类想法:
仿真: 仿真到真实的方法需要人类设计师指定机器人接受训练的环境并产生必要的资产。在仿真中学到的行为是这些选择的产物。通常,产生最佳结果的仿真并不是呈现准确的现实模型(这很困难),而是编码机器人应该对其具有鲁棒性的变化类型,例如在随机踏脚石或高度场上训练,这进一步强调了人类洞察力不仅指导任务是什么,而且间接指导如何解决任务。
人类视频: 纯粹从人类视频中学习机器人技能的方法通常需要定义人类和机器人之间的某种对应关系,例如手的位置或抓取的手指放置。任何这样的选择都假设了解决任务的特定方式(例如,通过用手使用力量抓取来拾取和移动物品),并且还需要弥合物理上可行的人类运动和机器人运动之间的巨大差距,无论是在动力学还是外观方面。
手持夹具设备: 我们可以在物理上施加人机映射,而不是在学习过程中定义映射,方法是要求人们使用模拟机器人夹具的手持设备收集数据。这真的很有吸引力,因为这样人们就必须以机器人化的方式执行任务。但仍然需要同样的"如何"决策——例如,设备假设机器人将在具有完整 6 自由度灵巧性的运动学工作空间中执行任务,仅使用手指,并且以不会暴露人类和机器人运动学或外观差异的方式。
所有这些方法都构成了有趣且相关的研究,并且都带来了一些优秀且令人兴奋的实际结果。然而,我认为在极限情况下,它们每一种都代表了一种妥协,最终会削弱大型学习模型的真正力量。
交集
当然,在收集数据时,人类判断是不可避免的:即使是最真实和纯粹的白板学习方法也需要我们定义我们希望模型做什么。但是,当我们试图回避对真实数据的需求时,我们所做的设计决策可能特别麻烦,因为它们固有地限制了问题的解决方式。对于每个域差距(仿真、视频等),我们被限制在实际上与我们的系统一起工作的行为、可以用我们选择的方法完成的行为(例如,在仿真中,或用手持夹具)以及关键的是,不会加剧域间差异的行为(例如,暴露没有机器人握着夹具,或暴露特别严重的仿真/真实世界差异)的交集内的解决方案。此外,随着我们使用更大更强大的模型,我们应该期望从这些问题中感受到更强的阻力:随着更强大的模型更紧密地拟合数据中的模式,它们会越来越多地拟合差异,就像它们拟合我们想要学习的真正可转移的模式一样。
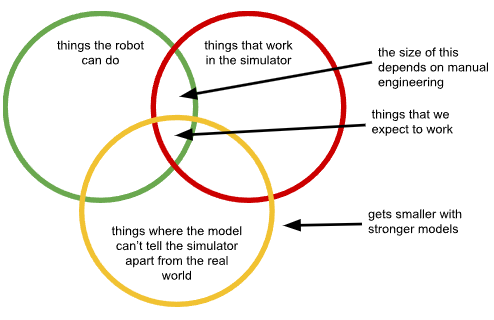
这些问题在研究项目和演示中可能看起来无关紧要,因为我们可以以使这种差异变得不那么重要的方式设置真实机器人,选择最佳和最鲁棒的策略恰好位于这个交集内的任务、环境和物体。但在真实的开放世界环境中,这不仅是限制性的,而且实际上削弱了训练大型和强大基础模型的主要优势。
首先,随着模型变得越来越强大,因此能够更好地区分代理数据域和目标真实世界域(即黄色圆圈收缩),这个交集变得更小。我们可以尝试通过从模型中隐藏信息、减少观察空间、使用域不变性损失、限制机器人可以使用的相机视图等来抵消这个问题。实际上,每种解决这些域差异的方法都归结为某种信息隐藏。但这又一次削弱了基础模型的主要优势,即它们综合复杂信息源并提取人类难以手动识别的微妙模式的能力。基本上,随着我们使用更强的模型,黄色圆圈变得更小,任何抵消这种情况的尝试最终都必须使模型变得更弱。我们只能通过对它们进行"脑叶切除术"来"愚弄"我们的模型,防止它们意识到自己在矩阵中。
这个交集的大小还严重依赖于我们在设计代理数据时所做的设计决策——这些设计决策越差,绿色和红色圆圈之间的交集就越小。在实践中,我们设计代理数据的设置(我们的仿真器,或手持数据收集设备),以便在我们考虑的几个应用域中,差异最小化,使得良好的动作(即导致成功的动作,或至少避免灾难性失败的动作)在这些应用域内的代理和真实机器人之间匹配。但无法保证它们在外部也会匹配。本质上,当我们在例如人类数据上训练我们的机器人基础模型,然后向它提出一个新问题时,它会尝试预测人类如何处理这个问题,而不是预测机器人的有效策略。这再次与基础模型的主要优势相反——即它们适用于许多问题的通用性和它们在将训练模式外推到新测试域时的泛化能力。现在,每个新域都需要更多的手动工程来改进我们的对应关系,而且当我们尝试泛化到更新颖的情况时,模型的泛化能力实际上与我们作对,加剧了代理数据和真实机器人之间的差距。
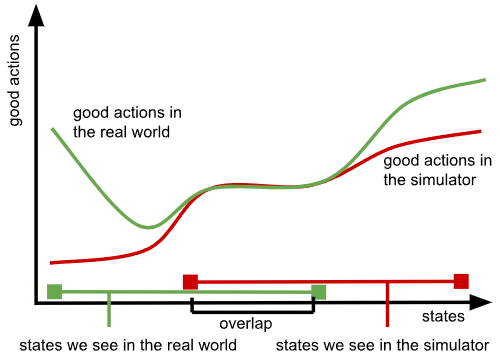
当我们实际上想要优化最佳可能行为时(例如,通过强化学习),所有这些问题都变得更加严重,因为我们无法利用真实机器人系统的全部能力,而不会超出机器人能做的事情、在代理数据中有效的事情以及模型无法区分差异的事情的狭窄交集。
真实的东西
在试图回避使用真实世界数据的需求时,我们试图找到一个两全其美的解决方案:既像仿真或网络视频一样便宜,又像在大型数据集上训练的真实基础模型一样有效。我们得到的是一个叉勺:在符合我们假设的少数情况下,它既可以做叉子的工作,也可以做勺子的工作,但通常它最终只是一个有洞的糟糕勺子或一个无效的钝叉子。
在机器学习中,一贯最有效的做法是确保训练数据与测试条件匹配。这就是真实的东西——教导模型世界如何真正运作的数据,以便它能够完成工作并提取潜在的模式,其中许多模式过于微妙和复杂,甚至人类都无法理解,然后从这些模式中推断出解决复杂新问题的方法。当我们用代理数据替代真实数据时,我们正在做次优选择:一个在几个特定条件下与真实交易匹配的代理。就像你不会通过对着挡板击球或观看罗杰·费德勒在电视上比赛来成为网球专家一样,尽管两者都复制了真正网球专业体验的某些方面,但机器人不会掌握真实世界,除非它能看到自己在真实世界中做事情。
我们应该从中得出什么结论?主要的结论是,如果我们要真正构建能够像大语言模型和视觉-语言模型在虚拟世界中那样在真实物理世界中广泛泛化的机器人基础模型,那么真实数据是不可或缺的。但我们也不应该把婴儿和洗澡水一起倒掉:保持务实很重要,就像大语言模型和视觉-语言模型使用大量与其最终目的相关性较低但包含有用世界知识的数据一样,我们的机器人基础模型也可以使用许多不同的数据源。毕竟,如果你想成为一个好的网球选手,观看罗杰·费德勒是有用的。如果我们在训练集中包含不同的数据,包括来自人类的数据甚至仿真数据,除了广泛和具有代表性的真实世界机器人经验,这很可能会有所帮助。事实上,这可能比试图完全回避真实世界数据的需求要容易得多:如果我们不再需要担心仅在机器人能力和我们的代理数据覆盖范围的交集中学习,那么可以放弃旨在减少域差距的拐杖,拥抱代理数据的本质:一个辅助的知识源,可以帮助你成为一个好的网球选手,它旨在补充而不是替代大量的真实世界实践经验。有了这种观点,我们可能也会对我们的代理数据提出非常不同的要求:我们不会试图紧密匹配真实世界的机器人实体(例如,通过使用手持夹具,或要求人们在视频中像机器人一样移动),而是像我们为大语言模型使用预训练数据一样使用代理数据——关于真实世界中可能发生什么的知识源,而不是智能体实际应该做什么的直接指令。
叉勺们
在这篇文章中,我讨论了代理数据,一个试图在没有大规模域内数据收集成本的情况下获得大规模训练好处的叉勺。这不是 AI 研究人员喜欢的唯一叉勺。其他叉勺包括结合手工工程和学习组件的混合系统,使用手工设计的约束来限制学习自主系统的不良行为的方法,以及将我们对问题应该如何解决的直觉嵌入到神经网络架构本身中的模型。它们都试图获得两全其美的效果:大规模机器学习的好处,而没有高数据需求或广泛目标设计(“对齐"或"后训练”)的伴随缺点。在某种深层次上,它们有很多共同点——用某种形式的手工设计的归纳偏差来解决不完整训练的挑战。因此,它们有同样的根本缺点:它们要求我们构建我们认为我们是如何思考的。大规模机器学习的成功归结于机器学习相对于人类设计的力量,理查德·萨顿称之为苦涩的教训。苦涩教训的一个推论是,对于任何启用学习的系统,任何不是学习的而是手工设计的组件最终都会成为其性能的瓶颈。叉勺很有吸引力,因为它们让我们认为我们可以通过强迫模型以特定方式解决问题来克服 AI 中的重大挑战,但最终这使我们的学习系统变得不那么可扩展,即使我们的意图是做恰恰相反的事情。
感谢 Karol Hausman、Brian Ichter、Lachy Groom 和 Chelsea Finn 对本文早期版本的反馈。